Design principles of Tarantool
I’m publishing a transcript of my talk at Highload Conference in Moscow in Spring 2015. It is actually the first part out of four (yes, I got a big conference slot back then :))
Here’s how I came to the idea of giving this talk. I don’t like speaking about new features, especially about upcoming features. While people enjoy listening to such talks, I don’t like spoiling the opportunity by presenting a feature before it’s ready. But people are also curious to learn how things work. So, this talk is about how it all works – or should work, from my perspective, – in a modern database management system (DBMS).
I’ll try to walk you through the entire implementation scale, from the macrolevel down to the microlevel, first dropping macroproblems to win ourselves some space and have design freedom in the middle and at the microlevels.
The macrolevel stands for the high-level design of a database. Is there any practical sense in coming up with a new DBMS implementation today? What’s the point of re-inventing the wheel, shouldn’t we rather use an existing open-source system and be happy with its performance, or tune and patch it, like Alibaba AliSQL or Facebook RocksDB? Indeed, something has to justify the cost of creating a new database from scratch.
After we establish some basic architecture principles, we’ll dig deeper and discuss engineering aspects. To process transactions, databases may use different sets of algorithms, like multiversion concurrency control or locking, but the performance also depends on how efficiently a preferred algorithm is implemented (in other words, how good you are at software engineering). While the right choice of an algorithm may boost the performance dozens of times, an optimal implementation may double or triple it, which also counts: when your product goes into production, you feel happy that a simpler solution doesn’t beat it hands down, because your database, despite having millions of features, is not paying an unreasonably high price for these features.
Part 2 of this talk is about high-level engineering principles. Here, I discuss how we work with the operating system and implement inter-thread communication. It lays the necessary groundwork for parts 3 and 4 by moving the problems of concurrency and system programming out of the way.
Parts 3 and 4 are the most technically advanced ones. Here, I’ll try to give a high-level overview of our home-made algorithms and data structures which would allow us to store and process data as fast and efficiently as possible.
So I’d like to begin the first part by asking the question:
Is there now, in year 2015, a window of opportunity for a new database management system?

Let me remind you the basic requirements defining the playing field. We should comply with the ACID principles. In my opinion, any database that thinks it can ignore ACID deserves no serious consideration. Sooner or later you’d throw it away as it becomes obvious that losing the entrusted data is no good, and consistency is not a scholastic demand, but essential part of being developer-friendly and actually caring about the data.
But ACID is an academic acronym, and while it conveys a mine of meaning even on a small slide like this, for a new database project, it’s necessary to understand and define all the nuances and distill the properties still meaningful and important today.
For example, when talking about DURABILITY, I usually explain it through the example of a nuclear war. Is your database DURABLE in case of a nuclear attack? Database durability is usually defined as durable on a non-volatile device, such as hard disk drive. But from a user’s point of view, it has to be defined in terms of sustained failures, be it a hard disk drive failure, computer, entire site or network. Causes and considerations for failure tolerance from the 70’s and 80’s are less relevant in the age of Internet: while in the 80’s most DBMS systems would sync the transaction log at commit to ensure disk durability and regard this sufficiently fail-safe, nowadays most Internet deployments avoid write-ahead log synchronization, but insist on replication, be it synchronous or eventually consistent. This observation goes a long way when it comes to designing a transaction and log managers: advantages of investing into a sophisticated algorithm for local transaction control, such as ARIES, grow dim if a good throughput of multi-master is more significant for users.
For ISOLATION, the definition says that the concurrent execution of two transactions mustn’t influence the outcome. Imagine I’m a smart guy with two laptops, and I use them both to connect to the database. On one laptop, I execute begin and insert, then check the result, make a decision knowing this result, and on the other laptop, I execute begin and insert for the data I’ve already seen. Hey, I’m so smart, have I cheated ISOLATION? While in this example it may be easy to see that protecting you from shooting yourself in the foot is not the database’s business, understanding whether the database ensures transaction isolation or not is much trickier in some fancy concurrent scenarios.
In my experience, most engineers, while having an intuitive understanding of ISOLATION, are less certain about corner cases, and their expectations often differ from the letter of the database book. So, should a modern database redefine isolation, like some eventually-consistent NoSQL solutions, provide a range of confusing choices, like those in the SQL standard, or rather focus on an efficient implementation which is easy to understand? Complicated isolation levels, be it eventual consistency, repeatable read or snapshot isolation, are often misused, and a new database should implement a more intuitive isolation model, without sacrificing the performance.
Indeed, ISOLATION, being the most fundamental ACID principle, heavily influences the performance. Providing transaction isolation requires participation of most parts of the database engine. For example, to ensure other transactions can proceed while your transaction is reading a row, we need to change both the data layout on disk and the way things operate at runtime; this, in turn, affects replication and backup, and even the network protocol.
The classical approach to the problem is multi-version concurrency control, when a private copy of the used data is kept for every transaction, protecting your transaction from interference of the others. This is how PostgreSQL or MySQL + InnoDB works. But when it comes to writing data, there is no way of fully isolating two participants attempting to update the same row at the same time: we could create a parallel universe for each transaction, but how would we later reconcile these universes into one?

Generally, we need to signal to the other participant that there is someone else working with the same data at the same time, or accept presence of phantoms - effects of violated transaction isolation. A formal way to define the problem is to introduce the concept of a transaction schedule (see the example on the slide above). We have data items (x and y), participants (1 and 2) and operations (r for read and w for write). The participants read or write the data, and E is the schedule of their actions.
Once we have transaction schedules written down, we can see their interference clearly, and see whether some coordination is necessary, or, in case transactions work on different subsets of data, whether isolated execution results are achievable without any coordination.

Long story short, the only mainstream approach to the coordination of interfering transactions is database locking. Your locking implementation could be pessimistic or optimistic, integrated with multiversion concurrency control or not, but there is no other practical way to ensure serializable isolation level. Some 20-30 years ago, the cornerstone of any database was the two-phase locking (2PL) theorem.

To make a serial schedule possible, participants must acquire locks on the objects they modify, and not release them until commit. Indeed, multiversion concurrency control, in some cases, allows avoiding these locks or postponing lock acquisition; validation at commit time reduces the locking window (the amount of time locks are kept), but potentially increases the abort rate. Sophisticated lock managers and schedulers exist, but, by and large, if you want to provide users with serial execution guarantees, you’re stuck with locking, and traditional DBMSs are based on it. And even if you break out of the local concurrency jail and implement an efficient local lock scheduler, the game is on again for multi-master consistency.


Being stuck with locking is not your only headache. Another bunch of problems arises from the fact that traditional DBMSs were designed in a reality where disk/memory proportions and performance were drastically different from what we have today. Those were the times when having 640 KB of RAM and 100 MB of HDD was fine. So, the proportion of capacities was roughly 1 to 100, while today it’s often 1 to 1,000. The change in performance is even more dramatic: RAM used to be only 100 times faster than HDD, and today it can be 1,000 or even 10,000 times faster.
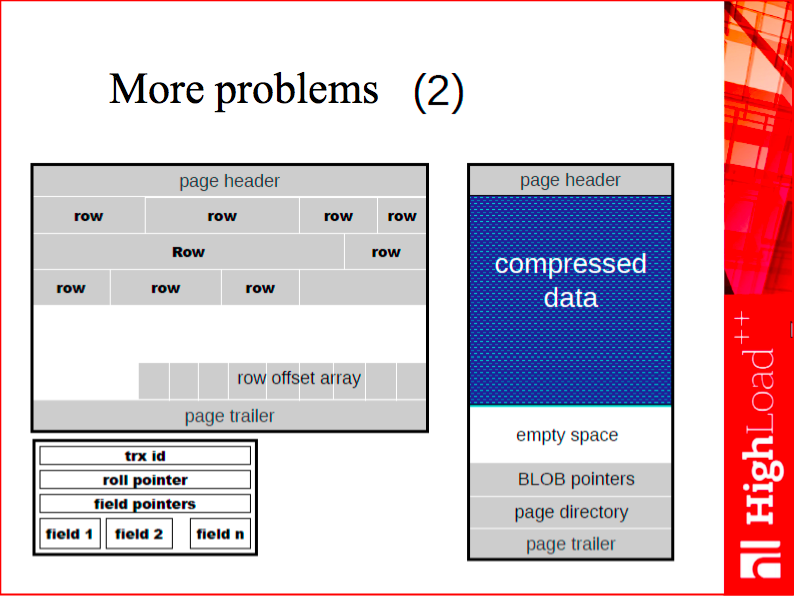
Here is a textbook example showing why the change in proportions matters so much. Traditional DBMSs are designed as two-level systems with two different data representations, on-disk and in-memory. In traditional databases, you use memory to actually cache the on-disk representation, and you’ll inevitably make tradeoffs between working efficiently with disk or memory.
Speaking of disk efficiency, take a look at the white space on the slide. This is a typical page of a typical DBMS that stores rows. As a rule, such pages are somewhat empty, because disk space is cheap, while the cost of writing to disk grows proportionally not to the size of the data we write, but to the number of disk accesses. As a result, it makes sense to leave some empty space on disk to avoid disk fragmentation and excessive seeks.
When it comes to memory efficiency, the situation is quite the opposite. Our goal here is to make the data occupy as little space as possible, because the cost of random access to RAM is roughly a constant value. So, it makes sense to store data in the most compact way. When you create an in-memory DBMS from scratch, it’s a good idea to revise the fundamental algorithms and data structures you’re going to use. For one thing, you may avoid wasted space as a result.
Going on with examples, here is another story. In disk-based databases, secondary keys are usually stored separately, as an extra set of database files or extra data in a table space. Secondary key is usually a collection of key values and references to table rows. Such a reference can take, for example, the form of either a primary key value or a physical offset of the row on disk. No matter what reference format is used, secondary keys take extra space and repeat a piece of every row, thus requiring extra maintenance on update.
Contrast this with an in-memory database, where, thanks to the low random access cost, a secondary key is fully memory-resident and can be a lightweight data structure with pointers to in-memory rows, taking a fraction of space and having low maintenance cost.
I’m stressing this since I often hear people say, “Why do we need DBMS X? We’re using DBMS Y, so let’s just give it more memory.” I saw such scenarios in action: people take a database designed for secondary storage, that is for storing data on disk (MySQL, PostgreSQL, MongoDB), provide it with a considerable memory space so that all the data fits in it - and feel happy for a few days or so. But this business plan is intrinsically faulty: with a database specially designed to keep 100% of data RAM-resident, a typical memory footprint (that is the amount of memory used) can be many times less just because there are no overheads incurred due to a different data representation.
To conclude, taking a DBMS designed for storing data on disk and using it to store all data in memory is wasteful practice.
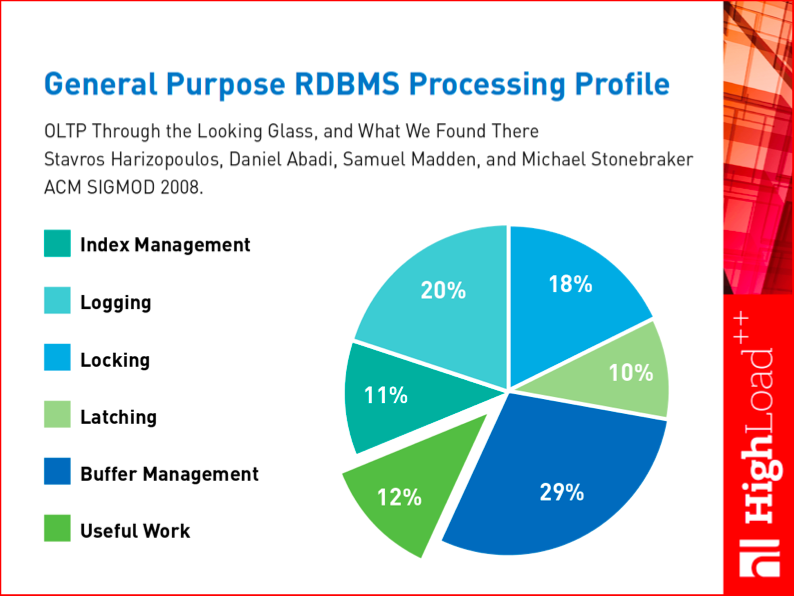
Here is a research that provides an excellent summary of the discussed problems. In 2008, a team of database mavens published an article where they analyzed the processing profiles of modern DBMSs. They analyzed how much effort a DBMS spent on various activities. They identified such major subsystems as locking and latching (latching is actually low-level locking, where we block interacting processes rather than data). And the conclusion was that only 12% of a modern DBMS’s efforts are spent on useful work, with all the rest distributed among the magical ACID properties and interaction with outdated architectures, that is on work based on outdated principles. That’s the diagram that illustrates the window of opportunity for new DBMSs, which can be dozens of times faster without sacrificing their functionality.
But practically speaking, how can we get rid of all this locking, latching and suchlike stuff? How can we avoid the overheads associated with storing data both in memory and on disk and converting between these representations? Enter the basic principles that formed the foundation of Tarantool.

In fact, this is no unique architecture. Take a look at Memcached, Redis or VoltDB - and you’ll see that Tarantool is not alone, so we start competing in our league, where we say that:
- we store 100% of data in RAM,
- we execute transactions consecutively, so no locking is needed (indeed, Tarantool doesn’t have any notion of locking, it just provides each transaction with exclusive access to the shared memory, and then Tarantool goes on to execute the next transaction).
Sharding is inevitable, so Tarantool fully supports horizontal scaling, but makes no attempts to vertically scale on a single machine. Indeed, today, even a typical single-unit machine is a supercomputer: 48 cores, each having a different cost of accessing RAM, that is you’ll get different access costs if you try to access the same RAM sector from different cores. As you see, techniques for ensuring a database server efficiently uses resources of a single computer are totally different from what they used to be some 10-20 years ago, so we’ve completely abandoned the concept of vertical scaling.
Now here’s the tricky part. We have a DBMS in RAM that executes all transactions sequentially. If we don’t want to lose data during transaction execution, we need to log this data, and we cannot skip this step. So, we have a write-ahead log, also known as transactional journal, stored on disk. If we write each transaction to the log, one after another, we’ll inevitably hit a performance bottleneck, because the disk is slow, and the fact that we use very little CPU capacity to execute the transaction won’t help here. A workaround may be writing to disk in big chunks, some 100 or 1,000 transactions at a time: write cost is largely a seek (disk head positioning) cost, and does not increase much with the increased chunk size. Thus, we’d spread writing costs across many transactions and increase the throughput. This won’t help us reduce the latency, though, because each transaction will still have the same latency that corresponds to writing-to-disk costs, but our throughput could be in millions of queries per second - with increased physical density of data on a device, typical disk bandwidth is usually quite high - so benchmarketing engineers would be really happy.

But once we allow chunking, we have another problem on hand: to batch multiple transactions in a chunk, we allowed neighbor transactions of a chunk to execute without waiting for their predecessors to commit. Now, we need to think of a way to roll back if logging fails. I haven’t come across this technique in literature, but for Tarantool we use an analogy to a film tape. Suppose we have a transaction already completed in memory and now we need to log it to disk. This transaction waits in the queue until its batch is accumulated and the slow disk write is done. While it’s waiting, we get another transaction that reads or updates the same data as its predecessor. So, we need to decide how to proceed in this case. If we block the second transaction’s execution, our performance will drop dramatically. But if we let it through, the earlier transaction queued for logging may fail, say, because we ran out of disk space. What shall we do with the successor then?
Rollbacks in Tarantool are done similarly to a tape rewind: if an error occurs, we stop our pipeline and rewind it backwards. We throw away all transactions that witnessed “dirty” data, negating their effect, and restart the pipeline. This is an awfully costly operation. We may abort some 10,000 transactions under heavy workload, but since this happens exceptionally rarely (never in production), it’s an acceptable cost.
Well, saying “never” is probably too emphatic, but if you monitor your hardware, this never happens in real life. Generally speaking, when designing a system, you’d better base your design on the most probable scenarios. If you’re trying to even out performance costs of all outcomes, whether it’s a commit or rollback, the system you build is very unlikely to be efficient, because your benchmark will be your worst-case scenario.
This concludes the first part of the transcript. In the second part, I will turn to the engineering matters, and design concurrency primitives we created for Tarantool. Stay tuned!