Picodata: вторая жизнь in-memory баз данных
Originally published on Habr.
Привет, меня зовут Костя Осипов, и я занимаюсь разработкой СУБД. На Хабре есть несколько моих статей про MySQL, Tarantool и про всякое-разное. Кроме того, я веду Telegram-канал, где делюсь инсайтами в области управления базами данных. Сегодня я выступаю в роли основателя компании Picodata, создающей одноимённую открытую СУБД, и управляющего директора ПАО Arenadata по исследованиям и разработке. Ниже — вольный пересказ моего недавнего доклада на HighLoad. Он про то, что нас ждёт в мире СУБД завтра, и, в частности, про место резидентных СУБД в архитектурах будущего.
Бэкграунд: эволюция аппаратного обеспечения и СУБД
Если вы, как и я, уже предсказывали тренды СУБД лет десять назад, вы любите посмеяться над собой. Среди различных нереализовавшихся прогнозов — и радикальное снижение стоимости оперативной памяти, и рост её доступных объёмов. Появление энергонезависимой оперативной памяти и исчезновение классических накопителей и SSD-дисков. Также активно прогнозировали переход на облачное, горизонтально масштабируемое аппаратное обеспечение и тотальную контейнеризацию. Не буду останавливаться сейчас на каждом тренде отдельно, подсвечу только главную фишку эпохи Webscale — горизонтальное масштабирование. Подход стал синонимом высоких нагрузок, и типичная СУБД будущего лет десять назад виделась именно как горизонтально масштабируемая, облачная, резидентная СУБД. Тема же сегодняшней статьи — совсем другое будущее, которое к тому же уже практически наступило.

Компания Pascari не так давно анонсировала свой очередной жёсткий диск на 122 TB. Похожие жёсткие диски планирует выпускать и Solidigm. Дело не только в большом объёме, но и в производительности ввода-вывода — один диск предоставляет 3 млн IOPS на чтение и 35 тыcяч IOPS на запись. В восьми таких дисках суммарно более петабайта данных, ну и дополнив конфигурацию современными процессорами на 96–128 ядер (взять хотя бы AMD EPYC 9xxxx), мы получаем мини-дата-центр в формфакторе двухъюнитового сервера. Соотношение размера диска к скорости записи такое, что для того, чтобы просто заполнить диск данными, нужно 12 и более часов.

Но если сверхбольшие накопители стали настолько доступны, нужно ли нам ещё горизонтальное масштабирование? Ведь многие современные СУБД, оптимизированные под многопоточность и большие объёмы памяти (например, тот же OrioleDB — форк PostgreSQL), показывают результаты, сопоставимые с кластерами на нескольких машинах.
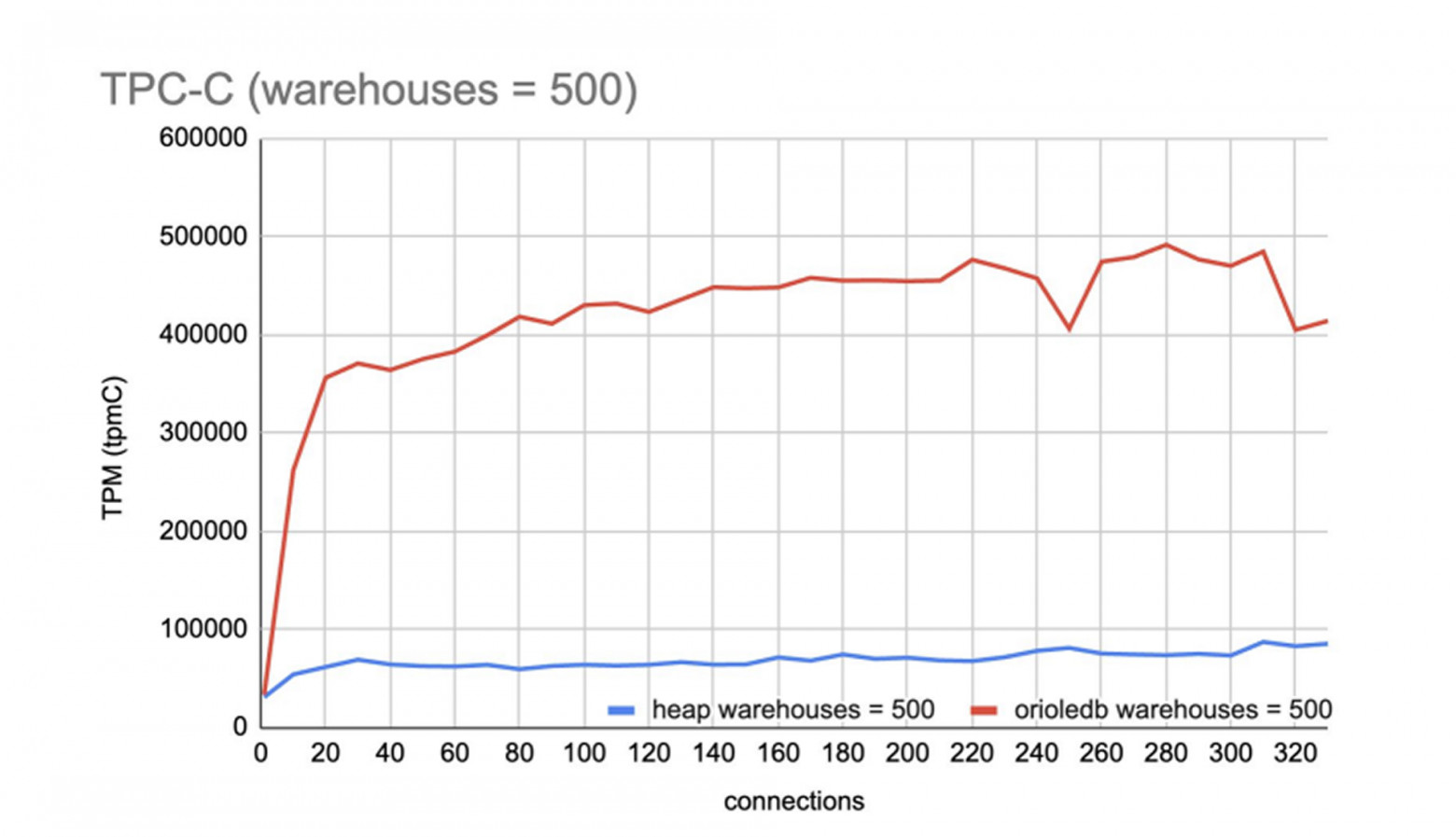
Есть и горизонтально масштабируемые системы, которые извлекают из одного узла на порядок бо́льшую скорость, чем классические СУБД. На скриншоте — ScyllaDB: на трёх средних узлах (32 ядра, 3,5 Ghz, 256 GB RAM) с фактором репликации 3 производительность составляет 500 000 запросов в секунду.
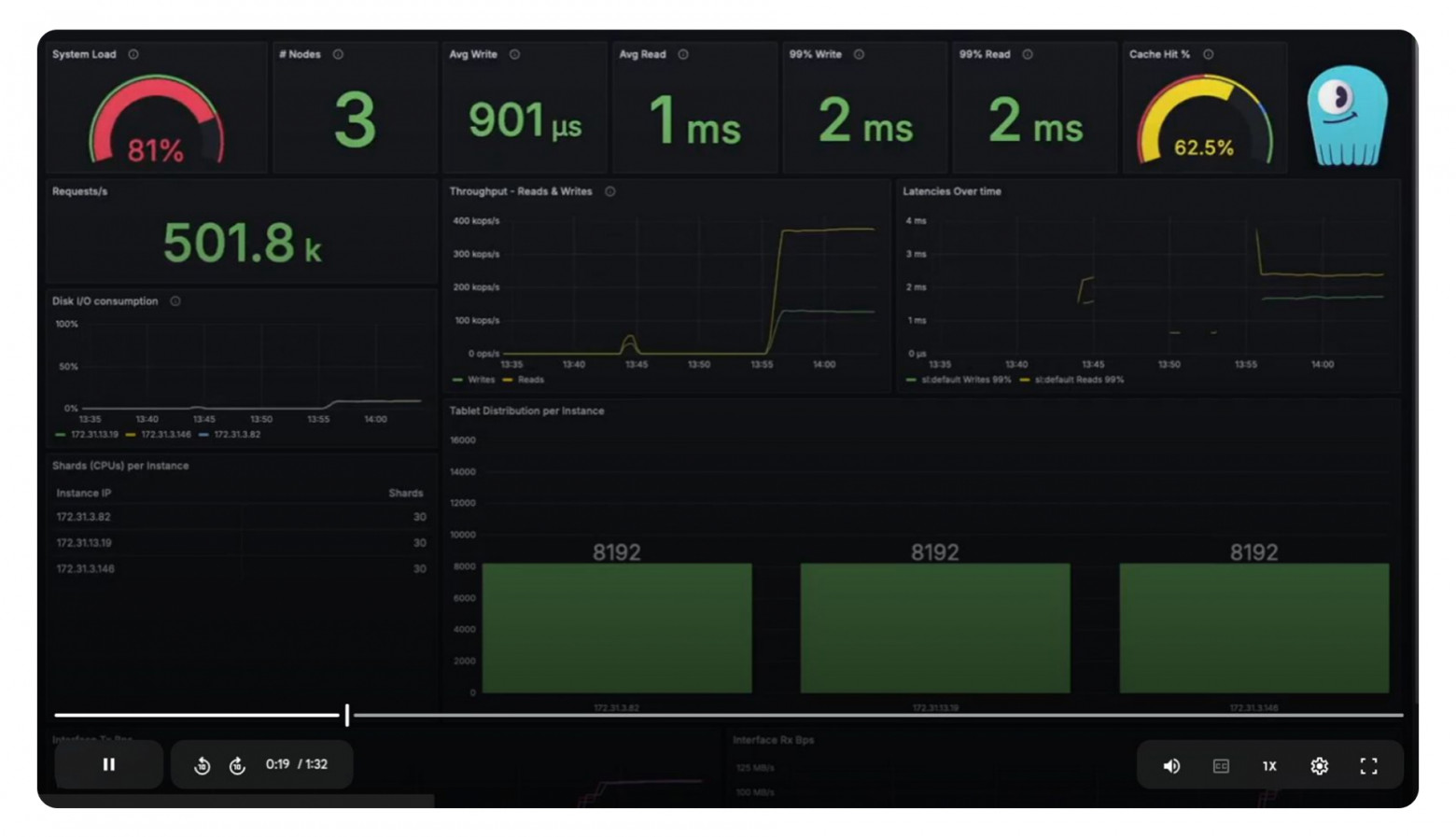
Напрашивается вывод, что дело не столько в противопоставлении горизонтальной и вертикальной масштабируемости, сколько во внутреннем устройстве СУБД, которое должно быть адекватно современному оборудованию.
Тренды в мире СУБД
Взрывной рост размера SSD-дисков и количества ядер на одном кристалле действительно является ключевым изменением в оборудовании сегодня, но мир СУБД был бы слишком скучен, если бы дело ограничивалось чем-то одним. Скажу пару слов о тенденциях современного мира данных.
-
Разделение compute и storage. Сама идея разделения вычислений и хранения противоречит принципу локальности данных (помните девиз Tarantool — bring compute close to storage), но с ростом популярности облаков такой подход, хотя и менее эффективный, сделался экономически оправданным: масштабировать вычисления стало проще, а хранение как сервис значительно подешевело. По мере роста объёмов данных всё чаще приоритет отдаётся снижению стоимости хранения, даже в ущерб скорости и эффективности обработки. Ещё одна причина популярности этого подхода — отставание кластерных СУБД от современных реалий: расширение и сжатие (шринк) кластера, работа в Kubernetes до сих пор считаются «особенными» операциями. Среди лидеров этого тренда — Trino, DuckDB с её облачной MotherDuck, Neon; в то же время существует и контртренд, например Turso. Можно предположить, что в ближайшие 5–10 лет эволюция снова приведёт нас к конвергентным архитектурам: рынок аналитики требует минимальной задержки, и запрос на near-real-time-аналитику становится всё более очевидным.
-
Закрытие исходного кода и ставка на облака
Вендоры всё активнее переходят на проприетарные лицензии. Среди примеров — MongoDB, Elasticsearch, ScyllaDB, Greenplum, CockroachDB, Timescale. Кто-то стремится защитить свой продукт от облачных провайдеров, кто-то — выстраивает модель продаж «база как сервис» (DBaaS). Деглобализация также вбивает осиновый кол в экосистему открытого ПО; здесь примерами послужат гонения на разработчиков по их территориальной принадлежности, глубокие форки открытых проектов, сделанные в Китае, всё большая консервативность мейнтейнеров крупных проектов. Также мы замечаем:
-
Фрагментацию лицензий: AGPL, BSL, SSPL. Переиспользование кода между non-free-лицензиями невозможно, что приводит к фрагментации ресурсов сообщества.
-
Глубокую привязку к облакам: многие СУБД теперь поставляются как managed service и вне этого окружения теряют часть возможностей.

На фоне усиливающегося давления на open source: переходов к проприетарным лицензиям, ограничений на использование кода и растущей зависимости от облачных провайдеров — всё меньше проектов остаются по-настоящему открытыми. В такой ситуации можно предположить, что в долгосрочной перспективе действительно открытыми останутся только платформенные игроки: не те, кто делает одну конкретную СУБД, а те, кто предлагает целую экосистему решений для работы с данными и не зависит от монетизации одного продукта.
Специализация и структуризация продуктов
Тренд на polyglot persistence не новый: он зародился около 15 лет назад с появлением горизонтально масштабируемых key/value-СУБД, таких как Cassandra, а также с развитием шин данных, прежде всего Kafka. Однако куда более показательно то, что, вопреки ожиданиям, консолидации рынка так и не произошло. Напротив, появляются всё новые специализированные СУБД — для задач искусственного интеллекта, аналитики, встраиваемые решения и так далее. По-настоящему новым трендом стал рост модульности в мире баз данных. Ещё 10 лет назад проекты, предлагающие «строительные блоки» для создания СУБД, можно было пересчитать по пальцам одной руки: в первую очередь это RocksDB, SQLite и H2. Их главное преимущество — возможность не разрабатывать все компоненты СУБД с нуля. Например, RocksDB используется в MySQL, ArangoDB, TiDB, Yugabyte и других, а FoundationDB построен на базе SQLite. При этом такие ключевые части, как, например, оптимизатор запросов, долгое время оставались немодульными. Сегодня ситуация начала меняться, и можно предположить, что в будущем СУБД всё чаще будут собираться из готовых компонентов — по аналогии с тем, как современные приложения собираются из библиотек и фреймворков.
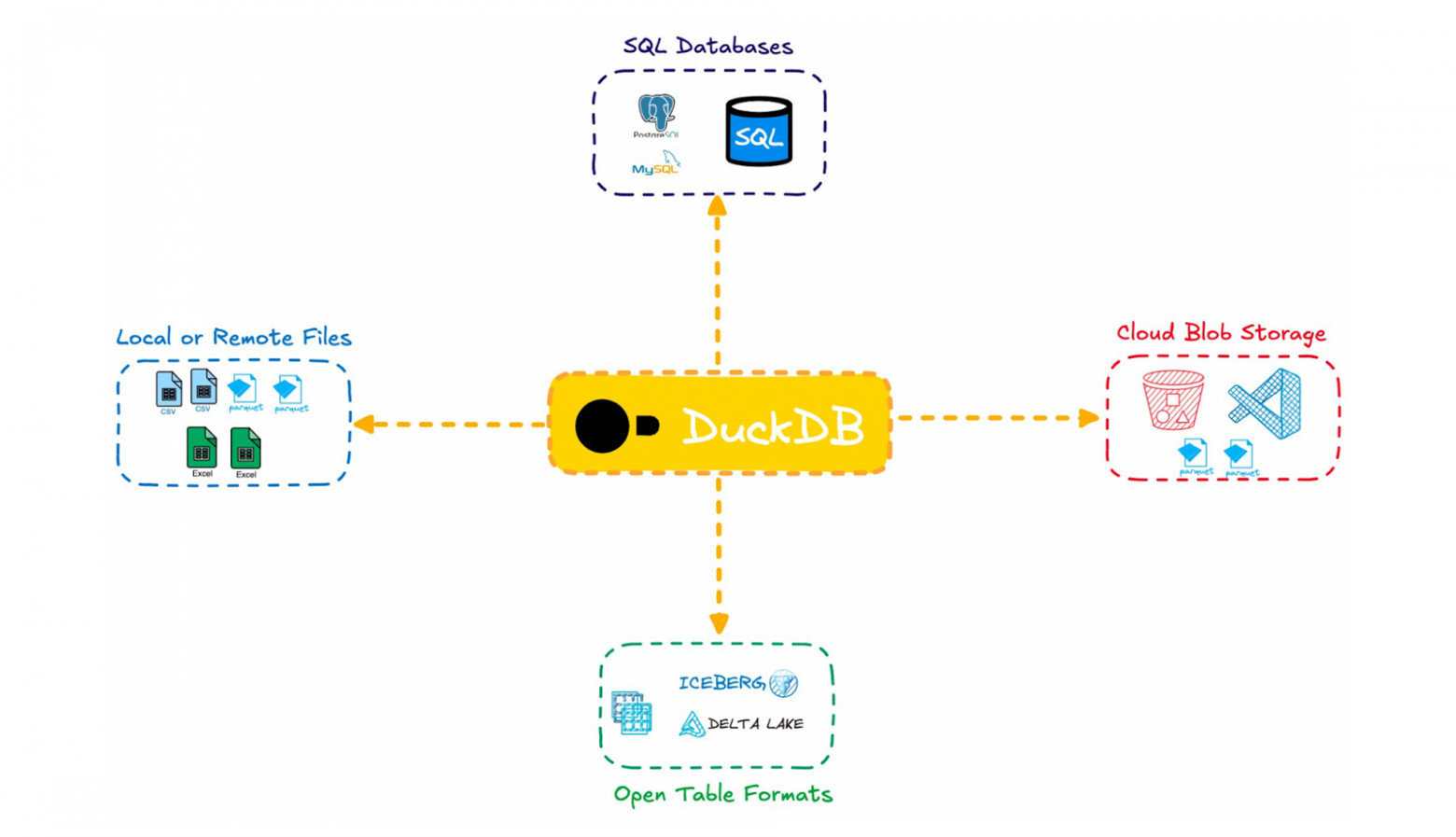
-
Apache DataFusion Kernel представляет собой аналитический оптимизатор запросов, который используется в разных продуктах.
-
etcd-raft используется как модуль репликации данных как в самом etcd, так и в CockroachDB.
-
cassandra-accord, реализация нового алгоритма управления транзакциями в Apache Cassandra изначально создана и развивается как отдельный проект.
-
DuckDB может быть использована далеко не только в контексте DuckDB Labs.
-
Turso переписал sqlite на Rust, сделав эту библиотеку доступной “нативно” для Rust экосистемы.
-
Dremio со своим проектом Apache Iceberg переопределяет ландшафт работы с холодными данными.
Всё это соответствует и изменениям в бизнес-ландшафте: CIO и CDO больше не принимают решения о покупке той или иной СУБД, а делают ставку на экосистему в целом (Amazon, Google или, например, в России — Sber Platform V, Yandex, Arenadata), а разработчику оставляют выбор конкретного инструмента в пределах экосистемы.
Место резидентных СУБД
Цель приведённого обзора — дать обоснование продуктовому видению Picodata, о котором я начну рассказывать далее. Так, например, появление больших и быстрых дисков означает, что скорость доступа к диску больше не может быть фактором выбора резидентной СУБД. Закрытие вендоров и переход в облака означают, что для того, чтобы сохраниться как продукт и сообщество, необходимо в первую очередь дать разработчикам удобный инструмент для решения типовых задач. Тренд на разделение compute и storage, эластичность означает, что добавление и удаление узлов в кластере и работа в Kubernetes должна стать рутиной и не влиять на производительность, пропускную способность и, главное, troubleshooting кластера. Разберёмся в этом более детально.
Резидентные СУБД достигают кратного прироста производительности не просто за счёт размещения данных в оперативной памяти. Действительно, тогда было бы достаточно дать PostgreSQL побольше памяти под кэш. Для кратного ускорения используются специализированные структуры данных, менеджеры транзакций, управление многозадачностью. Для горизонтального масштабирования применяется архитектурный подход shard-per-core: все данные сегрегируются по ядрам процессора, таким образом устраняются блокировки и конкуренция потоков за данные. Нужны ли все эти усилия, если скорости диска стало достаточно?
Чтобы ответ на этот вопрос стал очевидным, достаточно взглянуть на конкретные цифры. Время отклика современного SSD составляет 10–20 микросекунд, тогда как доступ к оперативной памяти (DIMM4) занимает всего 10–20 наносекунд. Несмотря на то что диски стали в 100 раз быстрее по сравнению с SAS HDD (средняя задержка — 1–2 миллисекунды), разница между SSD и памятью всё ещё составляет три порядка. Но что происходит, если между чтением и пользователем стоит операционная система и сеть? К задержке добавляются накладные расходы ОС — возьмём, например, 50 микросекунд, что соответствует размеру кванта планировщика в Linux по умолчанию. Плюс время передачи данных внутри дата-центра — около 200–300 микросекунд. В итоге общее время ответа складывается из всей этой цепочки, и легко увидеть, что сами операции чтения — будь то с диска или из памяти — становятся несущественными на фоне общей стоимости запроса в микросервисной архитектуре.
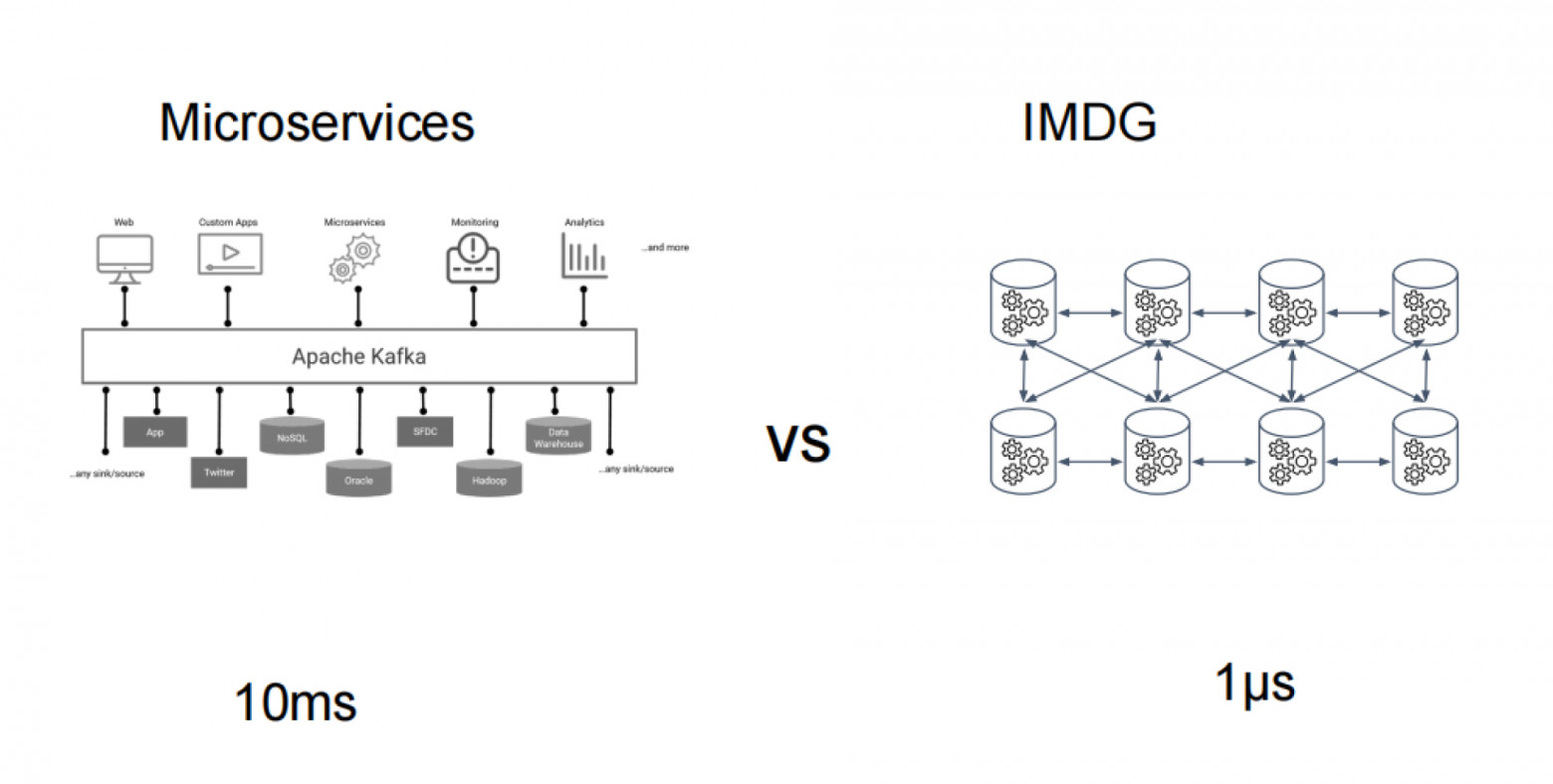
А что, если отказаться от идеи дезагрегации вычисления и хранения, и логику приложений, для которых скорость работы действительно критична, разместить внутри СУБД, в виде плагина или хранимой процедуры? И вот мы снова вернулись к ускорению на 3–5 порядков, которое даёт прямой доступ к данным.
Сценарии, когда подобного рода трансформация может быть оправдана:
- интеграция данных из разных источников в виде высокодоступной, массовой витрины - например, личный кабинет клиента для любой компании федерального масштаба;
- тарификация, высокочастотная торговля, real time bidding, рекламный таргетинг, скоринг в реальном времени;
- компрессия и анализ IoT данных на лету, платформы данных в промышленности;
- ускорение ERP, расчетные задачи (себестоимость, отчётность, заработная плата) для крупных вертикально интегрированных компаний.
Во всех этих случаях «чуть быстрее» может означать «существенно выигрываем в бизнесе».
Вот и выходит, что в то время, как вертикально масштабируемые СУБД снова набирают популярность благодаря быстрому росту мощности серверов, IMDG (in-memory data grid) подход не потерял свою релевантность.
Хранимые процедуры и подход микросервисов
Поговорим про ограничения данного подхода. Часть из них — в предубеждениях, но часть действительно существует, и хороший инструмент должен их учитывать.
В большинстве высоконагруженных проектов сегодня хранимые процедуры — это антипаттерн. Знаете ли вы, что ближайшим родственником SQL/PSM (это стандартный диалект PL/SQL) является ADA, созданный в 1980 году? Но дело даже не в архаичном синтаксисе.
Сложность управления процессом разработки
В мире микросервисов и DevOps мы привыкли хранить код в системе контроля версий, масштабировать вычисления stateless-контейнерами, накатывать обновления пакетами, тестировать всё в CI/CD, отлаживаться онлайн с помощью A/B-тестирования. Аналогов современным методам разработки в мире хранимых процедур просто нет. Ну или о них никто не говорит.
Сложность отладки и тестирования
Как запустить интерактивный отладчик, изолировать исключение или предотвратить возникновение hot spots на продуктивных данных? Для действительно высоконагруженных приложений нужны не только функциональные тесты, но и тесты производительности. В то же время практики тщательного покрытия тестами миграций схемы данных либо логики СУБД не слишком распространены: проще воспользоваться schema-less-подходом и хранить всё в json (до свидания не только производительность, но и качество данных).
Сложность обновлений
Как консистентно обновить логику внутри распределённого кластера без простоя? Инструменты вроде Flyway или Liquibase помогают мигрировать схемы, но с логикой в базе (особенно распределённой) они не работают. Кроме того, теперь версии схемы и кода хранимых процедур должны совпадать. При этом, если во время обновления что-то пошло не так, откатиться может быть невозможно.
Picodata предлагает как инструменты, так и методы по работе с перечисленными ограничениями. Далее поговорим о них.
Домены отказа, тиры и версионируемые плагины на Rust
Задам контекст. Задача любой кластерной СУБД — разделение данных между узлами таким образом, чтобы для пользователя они представляли единое целое.
Разделяем все данные на фрагменты — шарды, при этом каждый шард обслуживает один процесс СУБД, выполняющийся на одном ядре процессора. В катастрофоустойчивой конфигурации шард обслуживается несколькими процессами СУБД (инстансами), находящимися в разных дата-центрах, и каждый такой инстанс хранит полную копию данных шарда. Набор таких инстансов мы называем репликасетом.
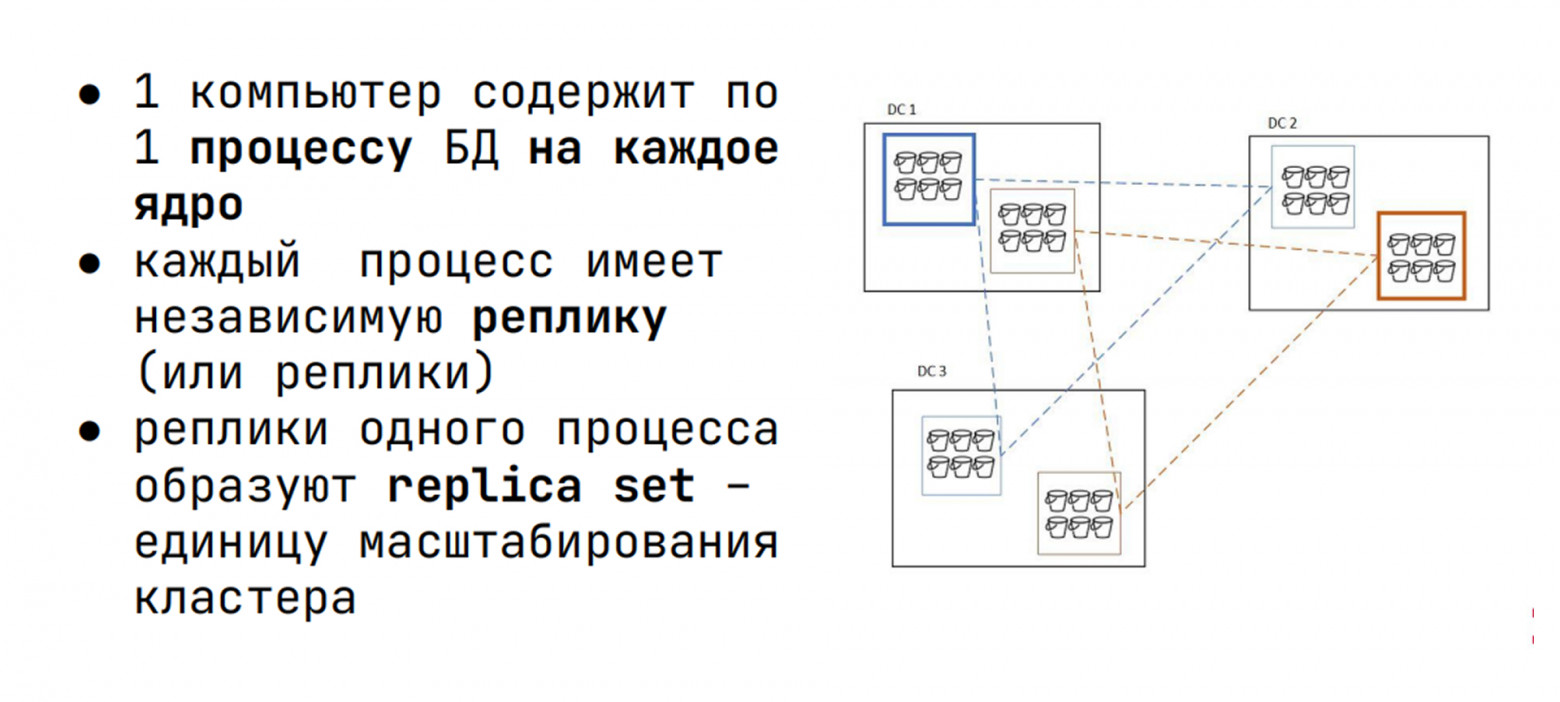
Для перебалансировки данных между шардами используется вторичное разбиение — бакеты. Бакет — это единица перебалансировки данных. Вместо того чтобы перемещать отдельные строки, мы перемещаем бакеты, каждый из которых имеет размер порядка десятков мегабайт — это позволяет гибко балансировать нагрузку при добавлении или удалении узлов.
Для управления кластером Picodata реализовала внутренний state provider (аналог etcd), который хранит метаданные в системных таблицах и реплицирует их на все узлы кластера с использованием raft-rs.
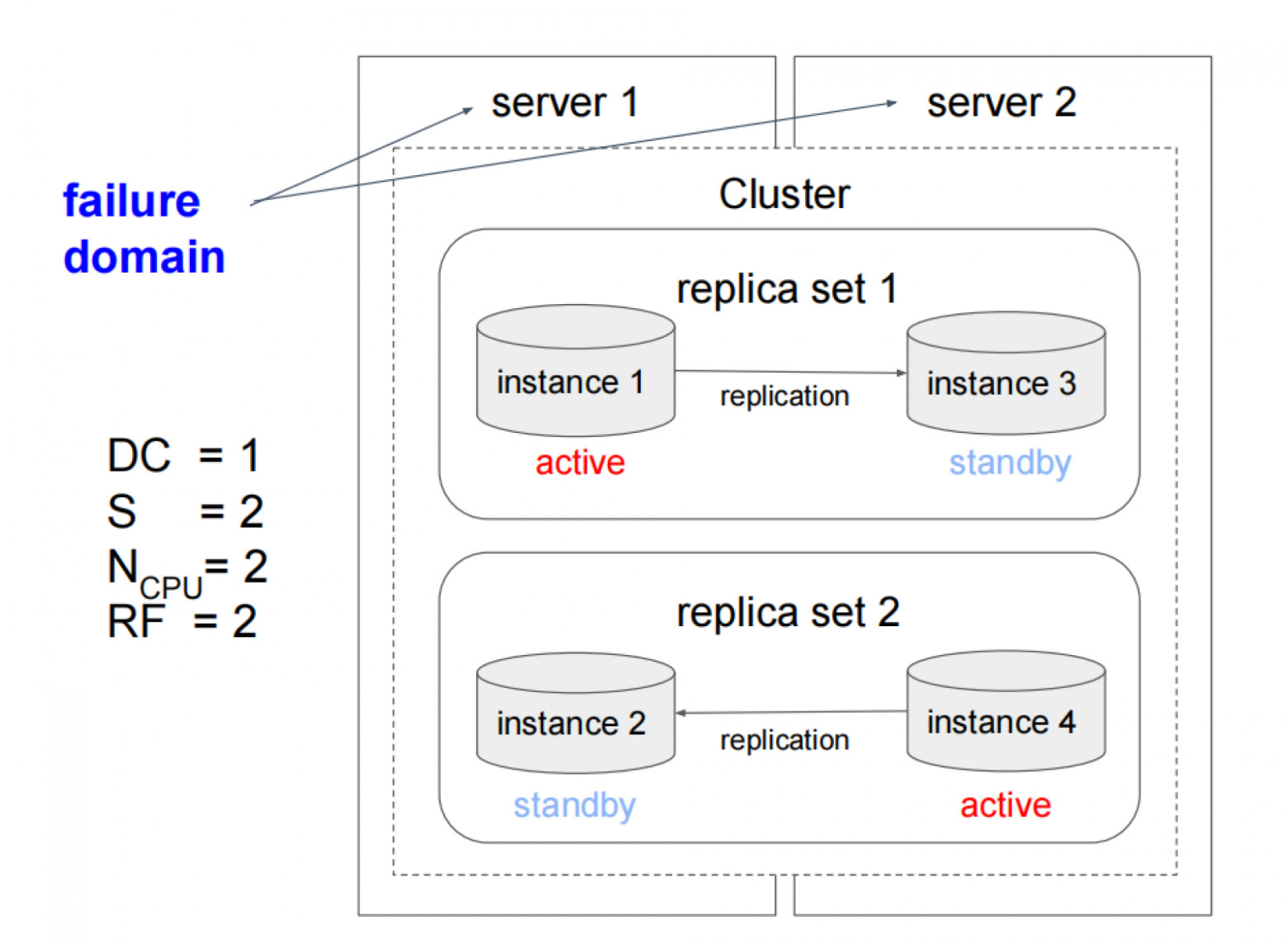
Домен отказа — это пара ключ/значение, которая описывает расположение узла в кластере. Например, datacenter: msk. Администратору необходимо лишь указать расположение при добавлении узла; кластер-менеджер автоматически скопирует состояние, определит пары для репликации и перераспределит данные.

Для управления кластером используются лишь две операции: добавить инстанс (add) или удалить инстанс (expel). Все процессы автоматически маршрутизируют запросы. Восстановление и перебалансировка выполняются автоматически.
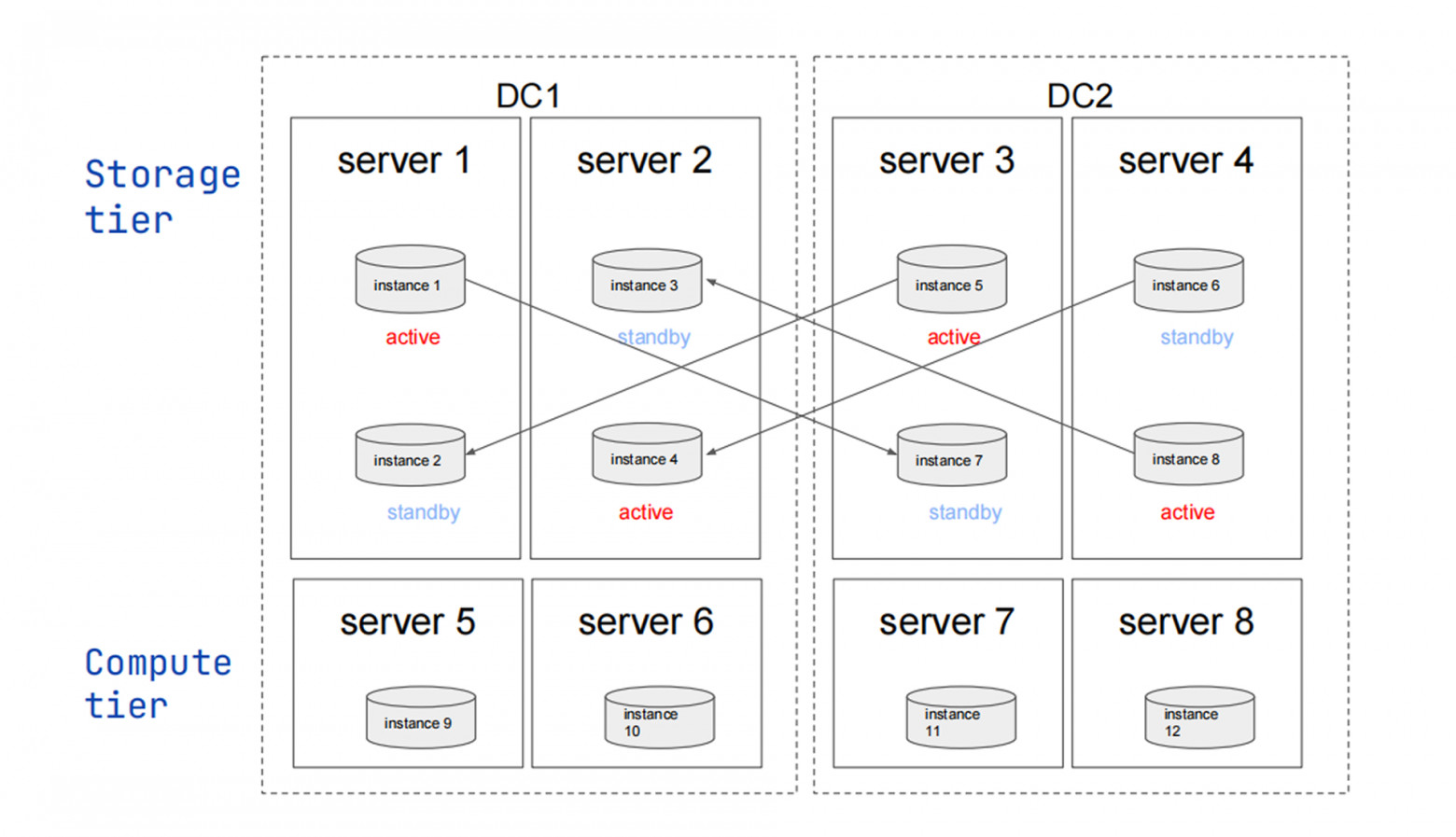
Тиры
Типовые кластера чаще всего состоят из одинаковых инстансов и выполняют одну задачу, но есть и более сложные сценарии, когда этого недостаточно. Например, необходимо выделить часть ресурсов кластера для вычислений, или развернуть конфигурацию 1+1 или 2+2, или хранить данные с разными уровнями надёжности, или использовать vinyl-движок для таблиц, превышающих объём оперативной памяти.
Каждый инстанс, таким образом, принадлежит строго одному домену отказа и одному тиру. Эта комбинация позволяет описывать различные топологии, включая симметричные (все домены содержат все тиры) и асимметричные конфигурации.
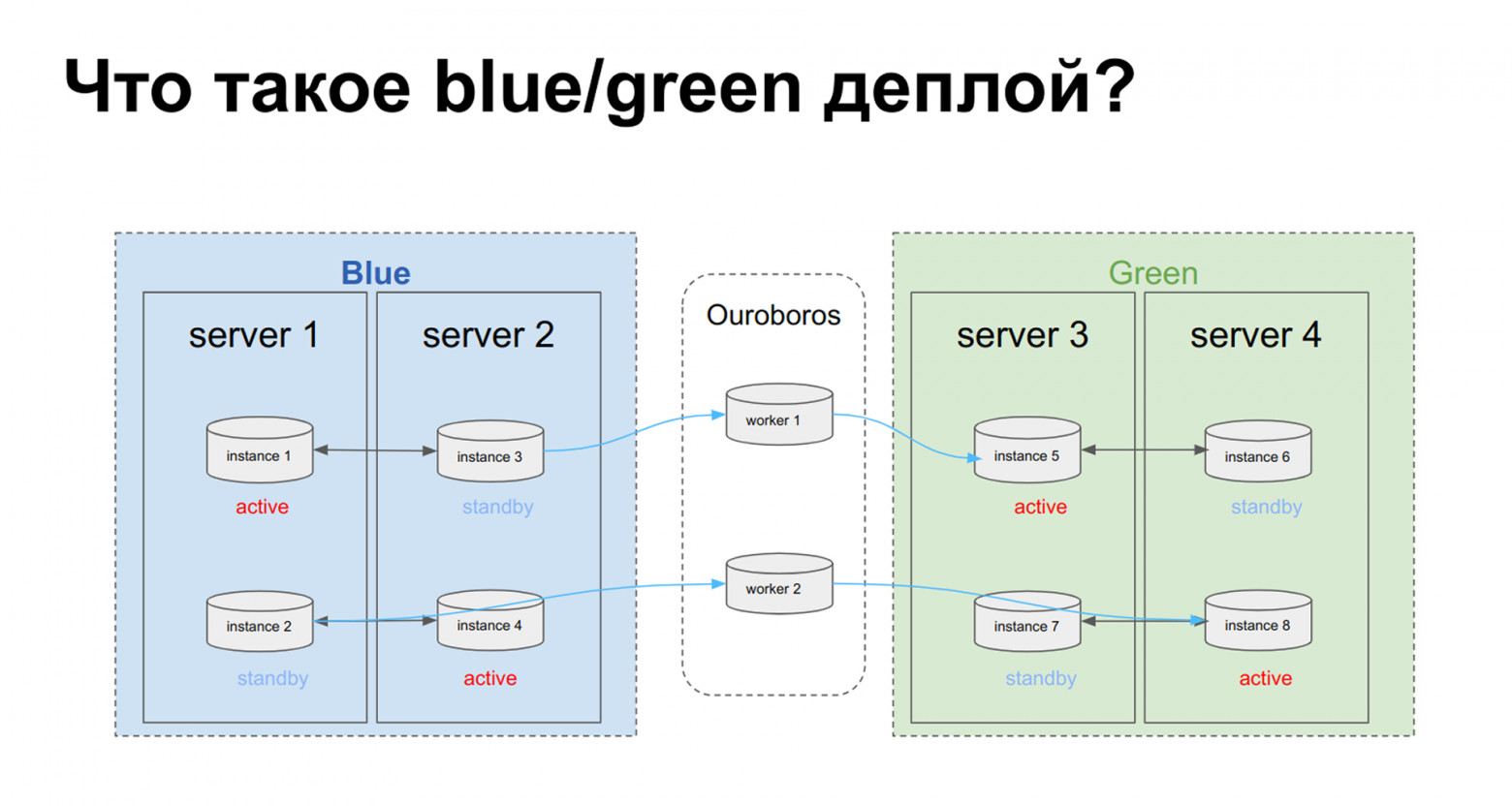
Управление кодом и миграциями: Blue-Green Deploy для плагинов
Подождите, всё красиво, наверное, но при чём здесь in-memory-вычисления? Домены отказа и тиры сами по себе не решают проблемы версионирования и отладки хранимых процедур. Для действительного blue/green-развёртывания требуются два кластера, соединённые репликационным каналом.
У каждого плагина есть версия (например, 1.0, 1.1), и в кластере не может одновременно существовать более двух разных версий одного и того же плагина (Blue — старая, Green — новая).
Манифест описывает плагин, его функционал и указывает на SQL-скрипты миграции. Миграции содержат секции up (запускаются при установке/обновлении) и down (откатывают изменения). Конфигурация хранится консистентно по всему кластеру; каждая версия имеет свой набор параметров. Enable/Disable операции синхронно активируют новую версию или деактивируют старую на всех узлах.
Процесс обновления:
- Установка новой версии плагина; Picodata регистрирует её как доступную.
- Выполнение миграции (up-скрипт) атомарно на всех узлах.
- Настройка параметров и привязка к тирам; конфигурация реплицируется.
- Включение новой версии; старая продолжает существовать для проверки.
- Отключение старой версии или откат через миграцию (down).
Для отладки без влияния на production реализован плагин ouroboros, осуществляющий логическую асинхронную репликацию между кластерами Picodata. Он позволяет создавать копии и реплицировать все или выборочные таблицы, тестировать новые версии независимо, затем переключаться на резервный кластер или устанавливать обновления на основной.
Picodata использует Rust как основной язык расширений с модульной архитектурой. Несколько плагинов взаимодействуют через общие данные (таблицы), а не через код, защищая production от конфликтов зависимостей. Утилита pike автоматизирует разработку и поставку плагинов в кластер.
SQL в Picodata
Плагины и расширения в Picodata имели бы крайне ограниченный функционал, если бы им не был доступен кластерный SQL. Работу SQL разработчики постарались сделать максимально эффективной.
Основным протоколом взаимодействия с СУБД мы сделали сетевой протокол PostgreSQL. Это означает, что работают многие инструменты PostgreSQL-экосистемы, например psql и DBeaver, а также многие драйверы.
В некоторых известных проектах (например, CockroachDB или TiDB) данные хранятся в едином пространстве «ключ-значение» (RocksDB, TiKV и так далее) и логика SQL реализована поверх NoSQL-хранилища. Это удобно для автоматического шардирования, но может порождать ненужные перемещения данных между узлами кластера во время JOIN.
Picodata передаёт управление коллокацией связанных данных в руки разработчика. Для сценариев работы с клиентом при создании схемы можно добиться того, чтобы все данные по одному клиенту находились на одном узле, а глобальные таблицы-справочники были идентичны на всех узлах. В результате: большинство бизнес-сценариев не потребует перемещения данных между узлами кластера; большинство транзакций будет выполняться локально на одном узле, т.е. конфликты транзакций и взаимные блокировки исчезнут; нагрузку на кластер можно будет действительно распараллелить.
Коллокация по ключу
По умолчанию данные разбиваются между всеми узлами кластера по ключу распределения.
Для управления коллокацией данных при создании таблицы используется расширение SQL DISTRIBUTED BY. Похожий синтаксис реализован в Greenplum. Если мы говорим DISTRIBUTED BY (client_id) для таблиц orders, payments, sessions, то все записи определённого клиента попадут на один узел в кластере.
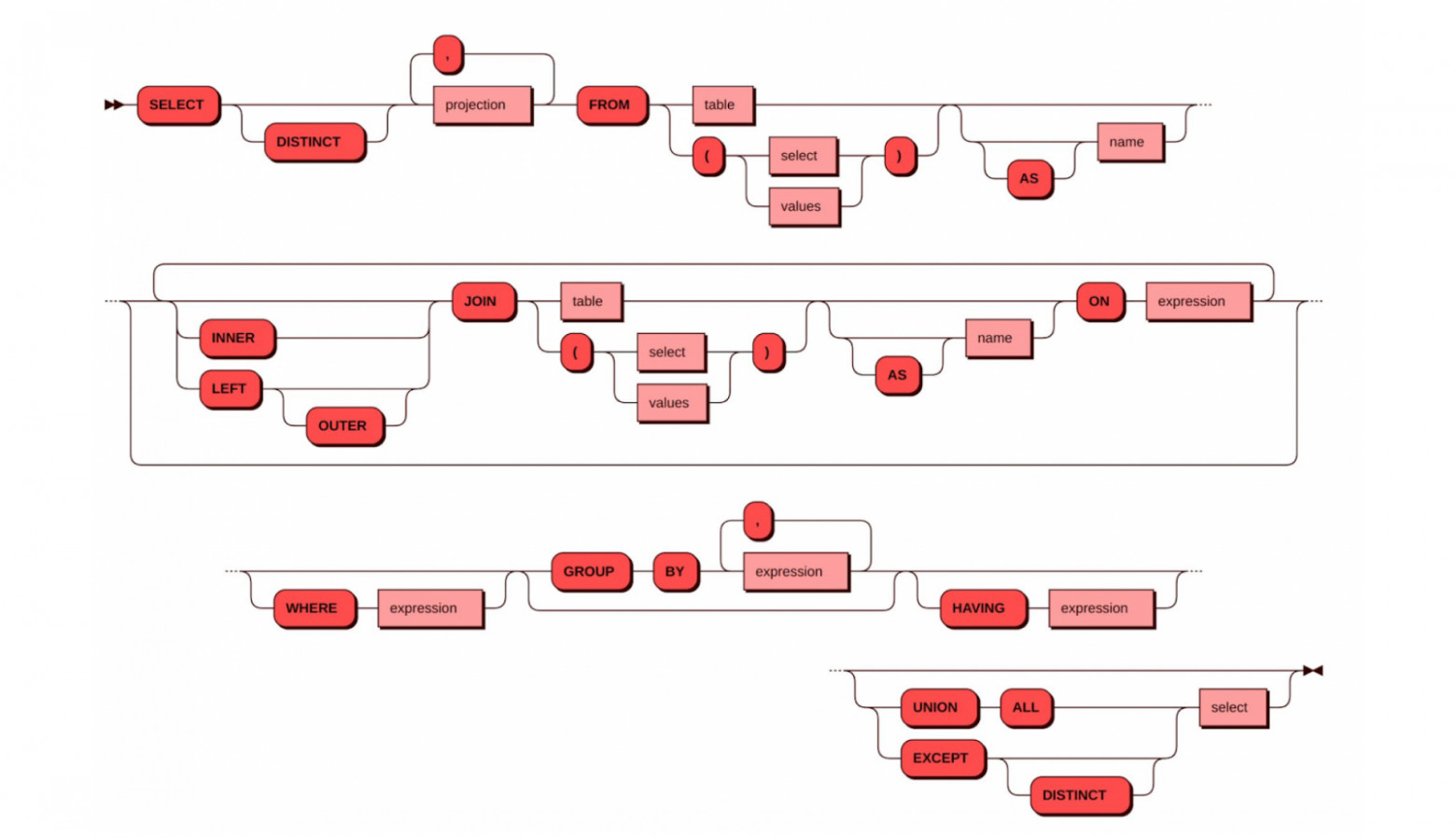
Глобальные таблицы
Для данных, необходимых на всех узлах, есть возможность задать глобальное (global) распределение. В аналитических сценариях глобальные таблицы используются для “small dimension table”: когда факт-таблицы распределены, а измерения глобальны.
Итоги
Можно сказать, что Picodata — это попытка переосмыслить in-memory-базы данных в эпоху, когда современное «железо» (миллионы IOPS, сотни терабайт на одном сервере) делает горизонтальное масштабирование далеко не всегда оправданным. Разработчики постарались создать удобный инструмент для специалистов, занимающихся действительно высоконагруженными проектами. В эпоху всеобщей смены лицензий и закрытия ключевых возможностей проект сохранил открытую лицензию BSD и продолжает инвестиции в открытое ПО. Для корпоративных клиентов предлагается версия с сертификатом ФСТЭК и коммерческими расширениями для работы с промышленными данными, миграции с проприетарных СУБД, замене Redis или Cassandra.
Каждый день в продукте появляются новые возможности. Версия 25.1 реализует оконные функции. В среднесрочных планах — материализованные представления, стоимостный оптимизатор запросов, колоночное хранение. Если будущее сложится так, что in-memory-СУБД заместят классические системы, такие как PostgreSQL и Oracle, то в локомотиве этого движения точно будет Picodata.