Хранение данных на Виниле
Originally published on Habr.
В 2016-м я выступил на Highload с докладом про Vinyl, движок для хранения данных на диске в Tarantool. С тех пор мы добавили много новых возможностей, но хранение данных на диске — такая объемная тема, что основы, о которых идет речь в этой статье, совсем не изменились.
Почему мы написали новый движок?
Как известно, Tarantool — транзакционная, персистентная СУБД, которая хранит 100 % данных в оперативной памяти. Основные преимущества хранения в оперативной памяти — это скорость работы и простота использования: базу данных не нужно тюнить, тем не менее, производительность остаётся стабильно высокой.
Несколько лет назад мы озадачились расширением продукта классической технологией хранения — как в обычных СУБД, когда в оперативной памяти хранится лишь кэш данных, а основной объём вытеснен на диск.
Движок хранения можно будет выбирать независимо для каждой таблицы, как это реализовано в MySQL, но при этом поддержка транзакций будет реализована с самого начала.
Первый вопрос, который мы себе задали: строить собственный движок, или взять готовую библиотеку? Хорошие библиотеки на рынке были: RocksDB, WiredTiger, ForestDB, NestDB, LMDB. Мы изучили их исходный код, взвесили за и против и решили писать с нуля.
Все сторонние библиотеки содержат сложные примитивы синхронизации для управления одновременным доступом к данным — ведь они подразумевают, что к данным одновременно обращаются несколько потоков операционной системы. Tarantool использует архитектуру на основе акторов: обработка транзакций в выделенном потоке позволяет обойтись без лишних блокировок и межпроцессного взаимодействия — накладных расходов, поедающих до 80 % процессорного времени многопоточных СУБД. Проектируя систему хранения с расчётом на кооперативную многозадачность, можно добиться оптимизаций, недоступных для многопоточных движков.
Алгоритм
В системах хранения принято выделять два основных подхода: B-деревья и LSM-деревья (Log Structured Merge Tree). Считается, что B-деревья более эффективны для чтения, а LSM-деревья — для записи. MySQL, PostgreSQL, Oracle используют B-деревья, а Cassandra, MongoDB, CockroachDB уже используют LSM.
B-дерево — это сбалансированное дерево, состоящее из блоков. Каждый блок содержит отсортированную коллекцию пар ключ-значение. Операция поиска требует logB(N) чтений блоков с диска, где B — количество пар ключ-значение в одном блоке, а N — общее количество элементов.
Write amplification
Рассмотрим, к примеру, операцию обновления одного элемента в B-дереве. Чтобы обновить один элемент в блоке, мы должны прочитать весь блок, обновить нужный элемент, записать блок обратно. Типичный размер блока — 4096 байт, типичный размер хранимого элемента — 100 байт. Следовательно, нам пришлось записать в 40 раз больше, чем реальный объём изменённых данных. Отношение размера фактически прочитанных (или записанных) данных к реально необходимому (или измененному) размеру называется паразитной нагрузкой, или write amplification. В нашем примере write amplification составляет приблизительно 40.
Ключевое отличие LSM
LSM хранит не данные, то есть ключи и значения, а операции с данными: вставки и удаления. Каждый элемент, помимо ключа и значения, содержит код операции — REPLACE или DELETE, а также порядковый номер операции log sequence number (LSN) — значение монотонно возрастающей последовательности, которое уникально идентифицирует каждую операцию. При этом всё дерево упорядочено сначала по возрастанию ключа, а в пределах одного ключа — по убыванию LSN.

Наполнение LSM дерева
В LSM-дереве разделение между памятью и диском явно присутствует с самого начала. Часть дерева в оперативной памяти называют L0 (level zero). Для L0 отводится фиксированная область, размер которой задаётся опцией vinyl_memory. Операции записываются в L0, упорядоченные по возрастанию ключа, а затем по убыванию LSN (log sequence number).
Когда количество элементов превысит размер L0, происходит дамп (dump) — L0 записывается в файл на диске и освобождается. Все дампы на диске образуют последовательность, упорядоченную по LSN: диапазоны LSN в файлах не пересекаются, а ближе к началу последовательности находятся файлы с более новыми операциями.
Файлы организованы в пирамиду, где более свежие файлы находятся вверху. Для удаления старых данных выполняется compaction (сборка мусора), объединяя несколько старых файлов в новый. При слиянии оставляется только более новая версия ключа.
Управление формой LSM-дерева
Если число файлов для поиска нужно уменьшить, то соотношение размеров файлов на разных уровнях увеличивается, и, как следствие, уменьшается число уровней. И наоборот, если нужно снизить стоимость слияний, соотношение уменьшается, создавая более высокую пирамиду.
Write amplification в LSM дереве описывается формулой log_x(N/L0)×x, или x×ln(N/C0)/ln(x).
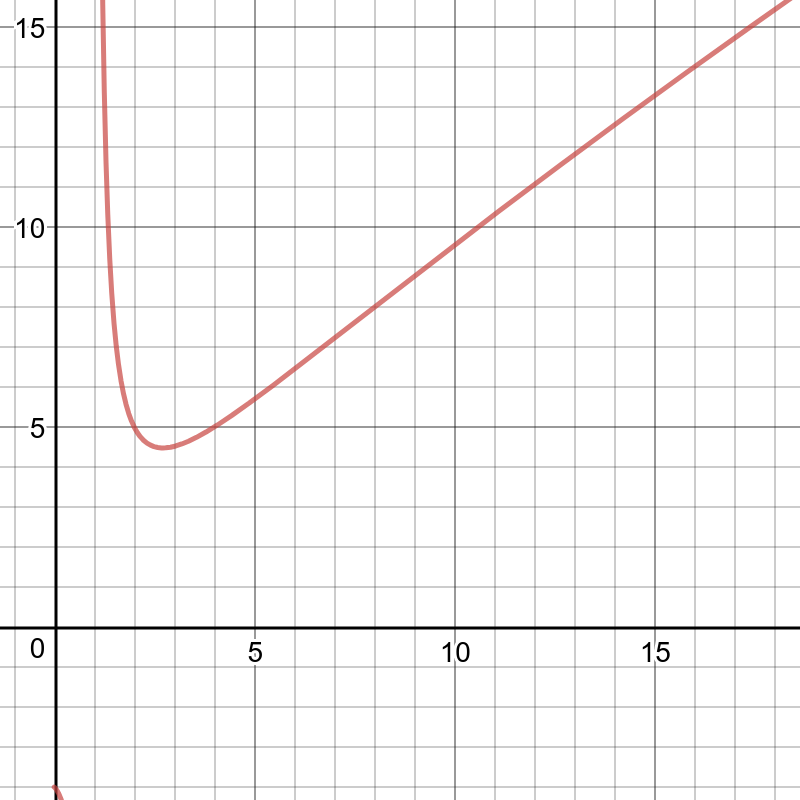
Read amplification при этом пропорционален количеству уровней.
Для стандартного дерева из 100 млн элементов с 256 МБ памяти и стандартными параметрами (vinyl_level_size_ratio=3.5, run_count_per_level=2) write amplification составляет приблизительно 13, а read amplification может доходить до 150.
Поиск
При поиске в LSM-дереве нам необходимо найти не сам элемент, а последнюю операцию с ним. Если эта операция — удаление, значит, элемента в дереве нет. Если вставка — поиск прекращается на первом совпадении.
В худшем случае значение в дереве изначально отсутствовало. Тогда поиск вынужден последовательно перебрать все уровни дерева, начиная с L0. Этот случай является на практике довольно частым — так, например, при вставке в уникальный индекс необходимо удостовериться, что элемента с таким ключом в дереве нет.
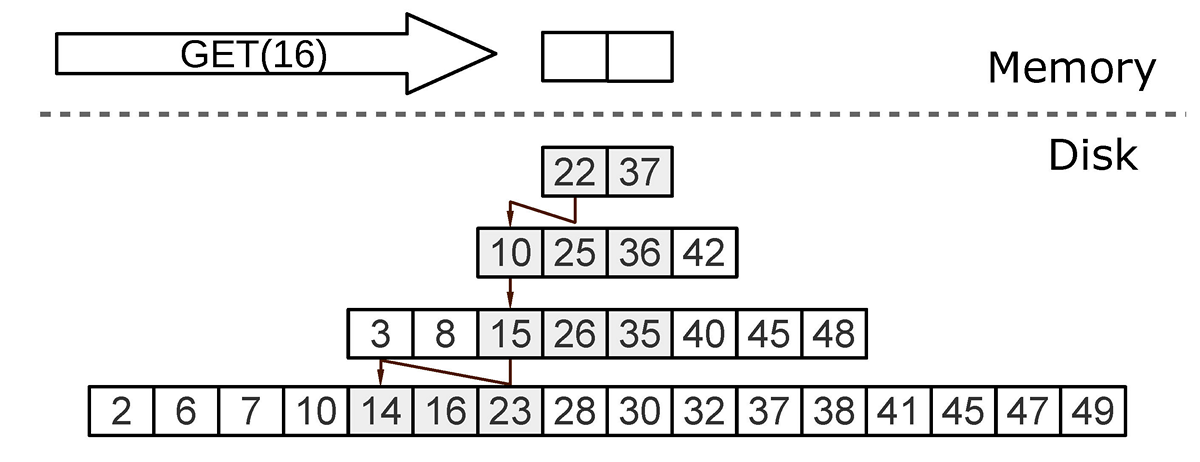
Для ускорения поиска «несуществующих» значений в LSM применяется вероятностная структура данных — фильтр Блума.
Поиск по диапазону
Если при поиске по одному ключу алгоритм завершается после первого совпадения, то для поиска всех значений в диапазоне, например, всех пользователей с фамилией «Иванов», необходимо просматривать все уровни дерева.
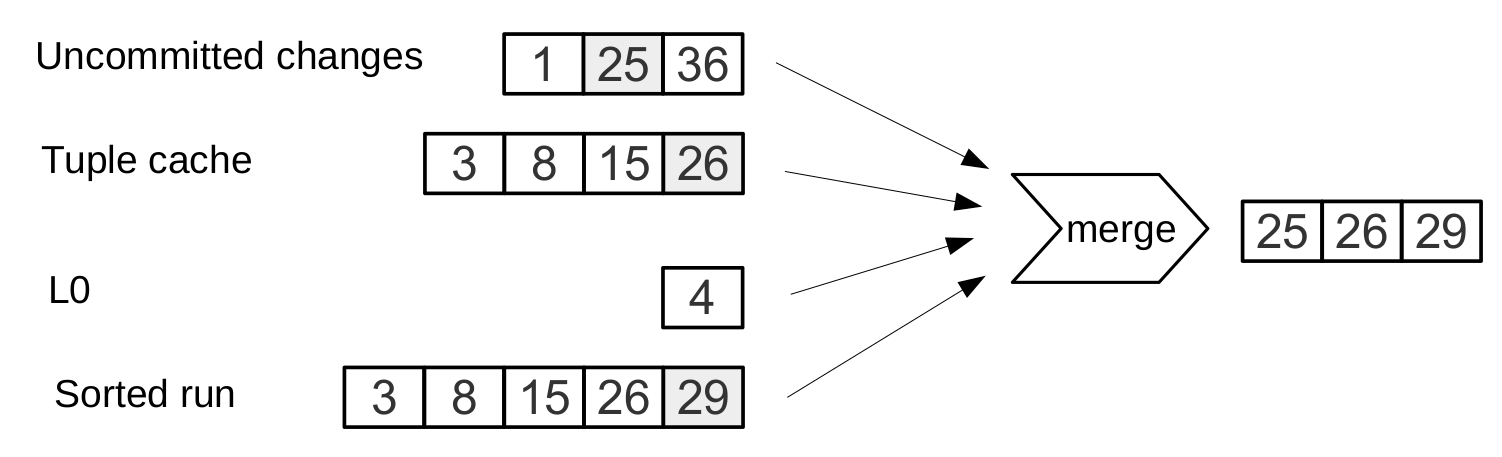
Формирование искомого диапазона при этом происходит так же, как и при слиянии файлов: из всех источников выбирается ключ с максимальным LSN, остальные операции по этому ключу отбрасываются, и позиция поиска смещается к следующему ключу.
Удаление
Роль операций удаления при поиске — сигнализировать об отсутствии искомого значения, а при слиянии — очищать дерево от «мусорных» записей.
Пока данные хранятся только в оперативной памяти, хранить удаления нет необходимости.
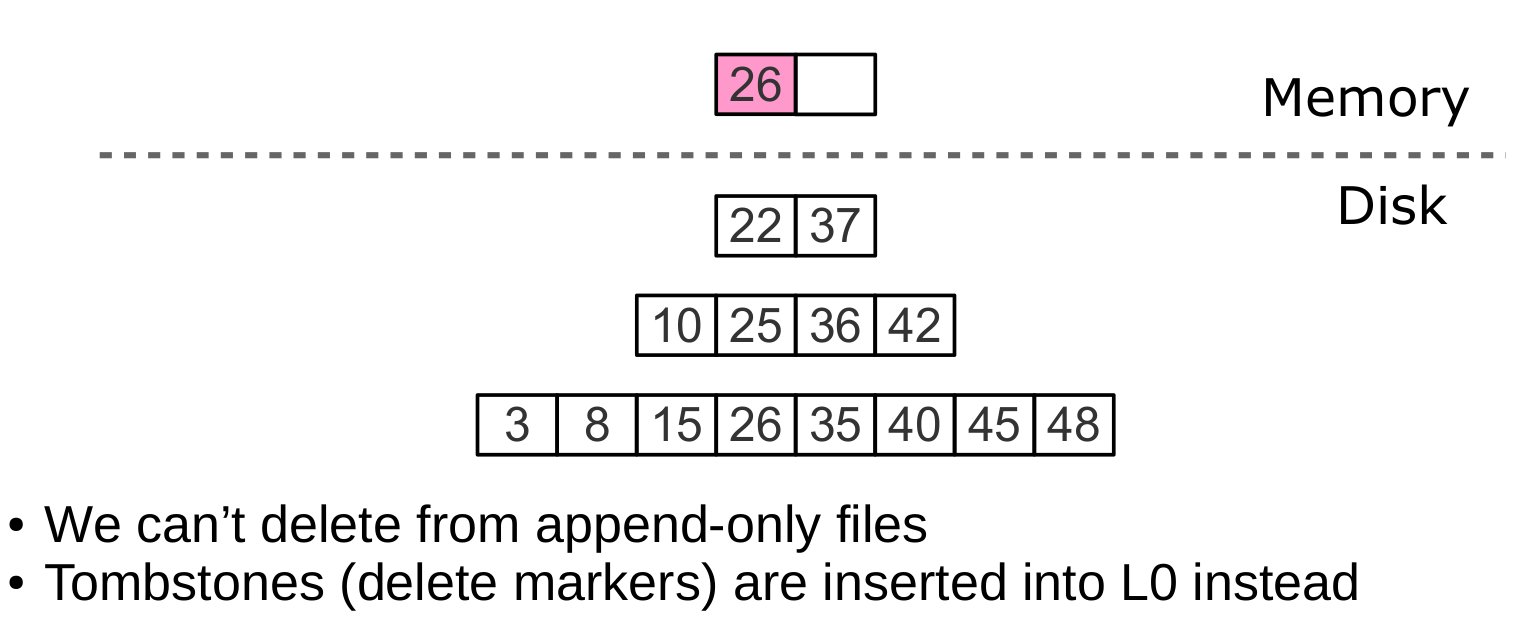
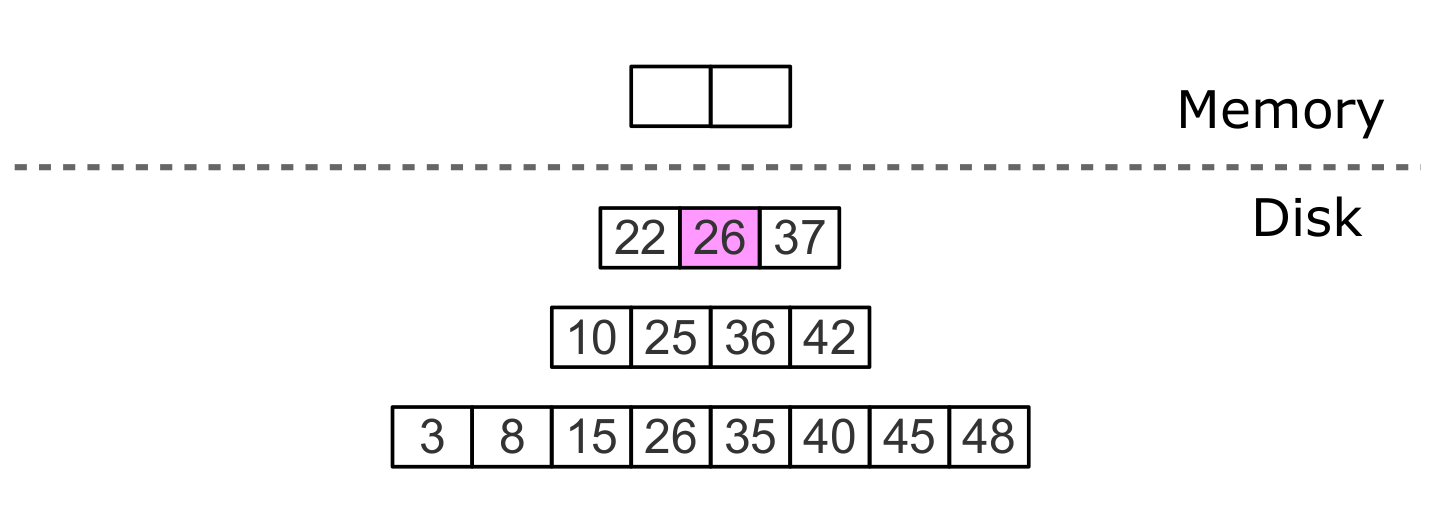
Нет необходимости сохранять удаления после слияния, затрагивающего самый нижний уровень дерева. Отсутствие значения в последнем уровне означает, что оно отсутствует в дереве.
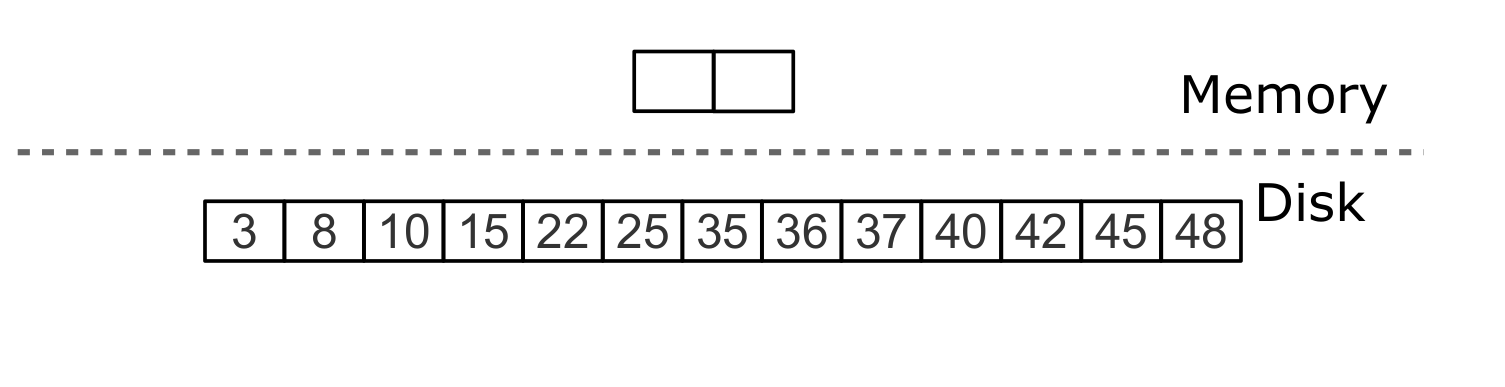
Если удаление следует сразу за вставкой уникального значения, операцию удаления можно фильтровывать уже при слиянии промежуточных уровней.
Преимущества LSM
Помимо снижения write amplification, подход с периодической выгрузкой (dump) уровня L0 и слиянием (compaction) уровней L1-Lk имеет ряд преимуществ перед подходом к записи, используемым в B-дереве:
- Dump и compaction пишут относительно большие файлы: типичный размер L0 составляет 50-100 MБ, что в тысячи раз превышает размер блока B-дерева.
- Большой размер позволяет эффективно сжимать данные перед записью. В Tarantool сжатие автоматическое, что позволяет ещё больше снизить write amplification.
- Издержки фрагментации отсутствуют, потому что в файле элементы следуют друг за другом без пустот/паддинга.
- Все операции создают новые файлы, а не меняют старые данные по месту. Это позволяет избавиться от столь ненавистных нам блокировок, при этом несколько операций могут идти параллельно, не конфликтуя друг с другом. Это также упрощает создание резервных копий и перенос данных на реплику.
- Хранение старых версий данных позволяет эффективно реализовать поддержку транзакций, используя подход multi-version concurrency control.
Недостатки LSM и их устранение
Одним из ключевых преимуществ B-дерева как структуры данных для поиска является предсказуемость: любая операция занимает не более чем logB(N). В классическом LSM скорость как чтения, так и записи могут может отличаться в лучшем и худшем случае в сотни и тысячи раз. Например, добавление всего лишь одного элемента в L0 может привести к его переполнению, что в свою очередь может привести к переполнению L1, L2 и т.д. Процесс чтения может обнаружить исходный элемент в L0, а может задействовать все уровни. Чтение в пределах одного уровня также требуется оптимизировать, чтобы добиться скорости, сравнимой с B-деревом. К счастью, многие недостатки можно скрасить или полностью устранить с помощью вспомогательных алгоритмов и структур данных. Систематизируем эти недостатки и опишем способы борьбы с ними, используемые в Tarantool.
Непредсказуемая скорость записи
Вставка данных в LSM дерево почти всегда задействует исключительно L0. Как избежать простоя, если область оперативной памяти, отведенная под L0, заполнена?
Освобождение L0 подразумевает две долгих операции: запись на диск и освобождение памяти. Чтобы избежать простоя во время записи L0 на диск, Tarantool использует упреждающую запись. Допустим, размер L0 составляет 256 MБ. Скорость записи на диск составляет 10 МБ/с. Тогда для записи L0 на диск понадобится 26 секунд. Скорость вставки данных составляет 10 000 запросов в секунду, а размер одного ключа — 100 байт. На время записи необходимо зарезервировать около 26 MБ доступной оперативной памяти, сократив реальный полезный размер L0 до 230 MБ.
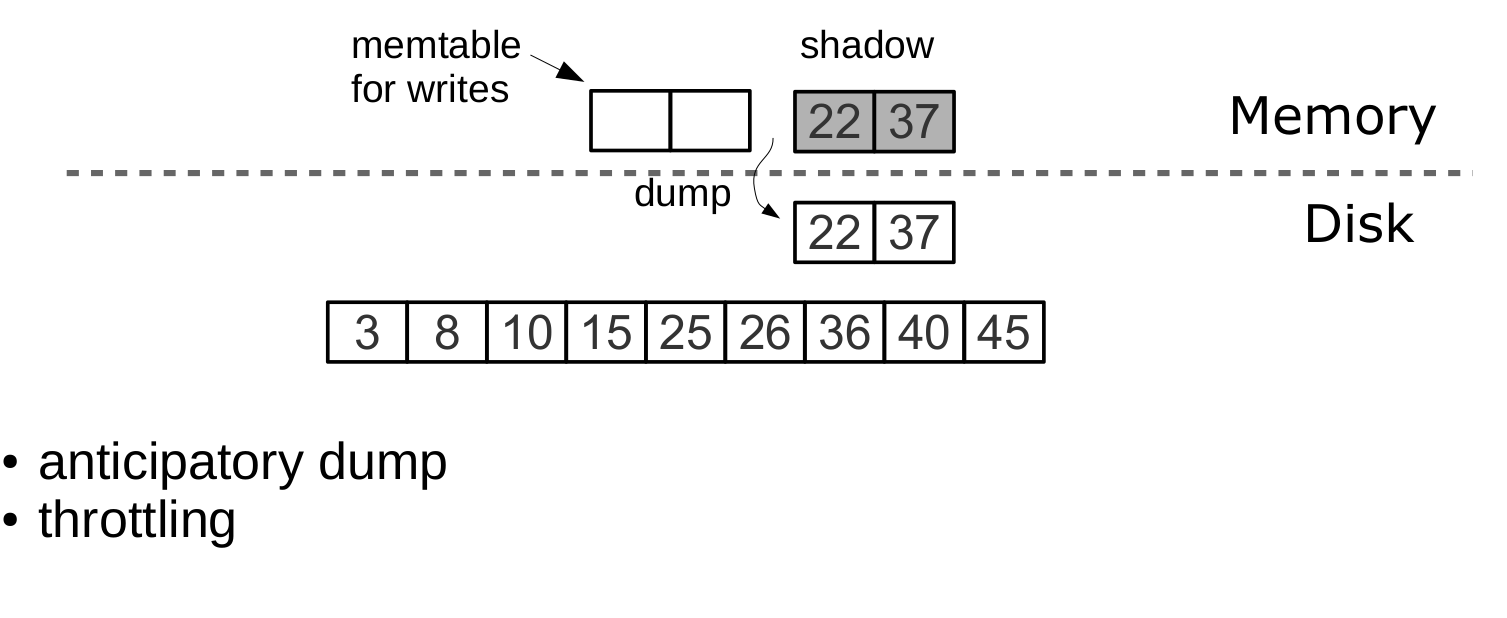
Все эти расчёты Tarantool делает автоматически, постоянно поддерживая скользящее среднее нагрузки на СУБД и гистограмму скорости работы диска. Это позволяет максимально эффективно использовать L0 и избежать таймаутов на ожидание доступной памяти для операций записи. При резком всплеске нагрузки ожидание всё же возможно, поэтому также существует таймаут для операции вставки (vinyl_timeout), значение которого по умолчанию составляет 60 секунд. Сама запись осуществляется в выделенных потоках, число которых (2 по умолчанию) задаётся переменной vinyl_write_threads. Значение 2 позволяет выполнять dump параллельно с compaction, что также необходимо для предсказуемой работы системы.
Слияния в Tarantool всегда выполняются независимо от дампов, в отдельном потоке выполнения. Это возможно благодаря append-only природе дерева — после записи файлы в дереве никогда не меняются, а compaction лишь создаёт новый файл.
К задержкам также может приводить ротация L0 и освобождение памяти, записанной на диск: в процессе записи памятью L0 владеют два потока операционной системы — поток обработки транзакций и поток записи. Хотя в ротированный L0 элементы не добавляются, он может участвовать в поиске. Чтобы избежать блокировок на чтение во время поиска, поток записи не освобождает записанную память, а оставляет эту задачу потоку обработки транзакций. Само освобождение после завершения дампа происходит мгновенно: для этого в L0 используется специализированный аллокатор, позволяющий освободить всю память за одну операцию.
Непредсказуемая скорость чтений
Чтение — самая сложная задача для оптимизации в LSM-деревьях. Главным фактором сложности является большое количество уровней: это не только кратно замедляет поиск, но и потенциально кратно увеличивает требования к оперативной памяти при почти любых попытках оптимизации. К счастью, append-only природа LSM-деревьев позволяет решать эти проблемы нестандартными для традиционных структур данных способами.
Компрессия и постраничный индекс
Компрессия данных в B-деревьях либо сложнейшая в реализации задача, либо больше средство маркетинга, чем действительно полезный инструмент. Компрессия в LSM работает следующим образом:
При любом дампе или слиянии мы разбиваем все данные в одном файле на страницы. Размер страницы задаётся опцией конфигурации vinyl_page_size, которую можно менять независимо для каждого индекса. Страница не обязана занимать строго то количество байт, что прописано в vinyl_page_size — она может быть чуть больше или чуть меньше, в зависимости от хранящихся в ней данных. Благодаря этому страница никогда не содержит пустот. Для сжатия используется потоковый алгоритм zstd от Facebook. Первый ключ каждой страницы и оффсет страницы в файле добавляются в так называемый page index — отдельный файл, позволяющий быстро найти нужную страницу. После дампа или слияния page index созданного файла также записывается на диск. Все .index-файлы кэшируются в оперативной памяти. Это позволяет найти нужную страницу за одно чтение из .run-файла (такое расширение имени файла используется в Vinyl для файлов, полученных в результате дампа или слияния). Так как данные в странице отсортированы, после чтения и декомпрессии нужный ключ можно найти простым бинарным поиском. За чтение и декомпрессию отвечают отдельные потоки, их количество определяется в опции конфигурации vinyl_read_threads.
Tarantool использует единый формат для всех своих файлов. К примеру, формат данных в .run-файле ничем не отличается от формата .xlog-файла, то есть файла журнала. Это упрощает бэкап и восстановление, а также работу внешних инструментов.
Bloom-фильтры
Хотя page index позволяет снизить число страниц, просматриваемых при поиске в одном файле, он не отменяет необходимости искать во всех уровнях дерева. Есть важный частный случай, когда необходимо проверить отсутствие данных, и тогда просмотр всех уровней неизбежен: вставка в уникальный индекс. Если данные уже существуют, то вставка в уникальный индекс должна завершиться с ошибкой. Единственный способ вернуть ошибку до завершения транзакции в LSM-дереве — произвести поиск перед вставкой. Такого рода чтения в СУБД образуют целый класс, называемый «скрытыми» или «паразитными» чтениями.
Другая операция, приводящая к скрытым чтениям — обновление значения, по которому построен вторичный индекс. Вторичные ключи представляют собой обычные LSM-деревья, в которых данные хранятся в другом порядке. Чаще всего, чтобы не хранить все данные во всех индексах, значение, соответствующее данному ключу, целиком сохраняется только в первичном индексе (любой индекс, хранящий и ключ, и значение, называется covering или clustered), а во вторичном индексе сохраняются лишь поля, по которым построен вторичный индекс, и значения полей, участвующих в первичном индексе. Тогда при любом изменении значения, по которому построен вторичный ключ, приходится сначала удалять из вторичного индекса старый ключ, и только потом вставлять новый. Старое значение во время обновления неизвестно — именно его и нужно «под капотом» читать из первичного ключа.
Например:
update t1 set city='Moscow' where id=1
Чтобы снизить количество чтений с диска, особенно для несуществующих значений, практически все LSM-деревья используют вероятностные структуры данных. Tarantool не исключение. Классический Блум-фильтр (Bloom filter) — это набор из нескольких (обычно 3-5) битовых массивов. При записи, для каждого ключа вычисляется несколько хэш-функций, и в каждом массиве выставляется бит, соответствующий значению хэша. При хэшировании могут возникнуть коллизии, поэтому некоторые биты могут быть проставлены дважды. Интерес представляют биты, которые оказались не проставлены после записи всех ключей. При поиске также вычисляются выбранные хэш-функции. Если хотя бы в одном из битовых массивов бит не стоит, то значение в файле отсутствует. Вероятность срабатывания Блум-фильтра определяется теоремой Байеса — каждая хэш-функция представляет собой независимую случайную величину, благодаря чему вероятность того, что во всех битовых массивах одновременно произойдёт коллизия, очень мала.
Ключевым преимуществом реализации Блум-фильтров в Tarantool является простота настройки. Единственный параметр конфигурации, который можно менять независимо для каждого индекса, называется bloom_fpr (fpr — сокращение от false positive ratio), который по умолчанию равен 0,05, или 5%. На основе этого параметра Tarantool автоматически строит Блум-фильтры оптимального размера для поиска как по частичному, так и полному ключу. Сами Блум-фильтры хранятся вместе с page index в .index-файле и кэшируются в оперативной памяти.
Кэширование
Многие привыкли считать кэширование панацеей от всех проблем с производительностью. В любой непонятной ситуации добавляй кэш. В Vinyl мы смотрим на кэш скорее как на средство снижения общей нагрузки на диск, и, как следствие, получения более предсказуемого времени ответов на запросы, которые не попали в кэш. В Vinyl реализован уникальный для транзакционных систем вид кэша: range tuple cache. В отличие от RocksDB, например, или MySQL, этот кэш хранит не страницы, а уже готовые диапазоны значений индекса, после их чтения с диска и слияния всех уровней. Это позволяет использовать кэш для запросов как по одному ключу, так и по диапазону ключей. Поскольку в кэше хранятся только горячие данные, а не, к примеру, страницы (в странице может быть востребована лишь часть данных), оперативная память используется наиболее оптимально. Размер кэша задаётся переменной конфигурации vinyl_cache.
Управление сборкой мусора: ranges
В Vinyl устройство одного LSM-дерева — это лишь фрагмент пазла. Vinyl создаёт и обслуживает несколько LSM-деревьев даже для одной таблицы (space) — по одному дереву на каждый индекс. Но даже один единственный индекс может состоять из десятков LSM-деревьев. Давайте попробуем разобраться, зачем.
Рассмотрим наш стандартный пример: 100 000 000 записей по 100 байт каждая. Через некоторое время на самом нижнем уровне LSM у нас может оказаться файл размером 10 ГБ. Во время слияния последнего уровня мы создадим временный файл, который также будет занимать около 10 ГБ. Данные на промежуточных уровнях тоже занимают место — по одному и тому же ключу дерево может хранить несколько операций. Суммарно для хранения 10 ГБ полезных данных нам может потребоваться до 30 ГБ свободного места: 10 ГБ на последний уровень, 10 ГБ на временный файл и 10 ГБ на всё остальное. А если данных не 1 ГБ, а 1 ТБ? Требовать, чтобы количество свободного места на диске всегда в несколько раз превышало объём полезных данных, экономически нецелесообразно, да и создание файла в 1ТБ может занимать десятки часов. При любой аварии или рестарте системы операцию придётся начинать заново.
Рассмотрим другую проблему. Представим, что первичный ключ дерева — монотонная последовательность, например, временной ряд. В этом случае основные вставки будут приходиться на правую часть диапазона ключей. Нет смысла заново производить слияние лишь для того, чтобы дописать в хвост и без того огромного файла ещё несколько миллионов записей.
А если вставки происходят, в основном, в одну часть диапазона ключей, а чтения — из другой части? Как в этом случае оптимизировать форму дерева? Если оно будет слишком высоким, пострадают чтения, слишком низким — запись.
Tarantool «факторизует» проблему, создавая не одно, а множество LSM-деревьев для каждого индекса. Примерный размер каждого поддерева задаётся переменной vinyl_range_size и по умолчанию равен 1 ГБ, а само поддерево называется range.
Изначально, пока в индексе мало элементов, он состоит из одного range. По мере наполнения, суммарный объём может превысить vinyl_range_size. В этом случае выполняется операция split — деление дерева на две равные части. Разделение происходит по срединному элементу диапазона ключей, хранящихся в дереве. Например, если изначально дерево хранит полный диапазон -inf… +inf, то после сплита по срединному ключу X мы получим два поддерева: одно будет хранить все ключи от -inf до X, другое — от X до +inf. Таким образом, при вставке или чтении мы однозначно знаем, к какому поддереву обращаться. Если в дереве были удаления и каждый из соседних диапазонов «похудел», выполняется обратная операция — coalesce. Она объединяет два соседних дерева в одно.
Split и coalesce не приводят к слиянию, созданию новых файлов и прочим тяжеловесным операциям. LSM-дерево — это всего лишь набор файлов. В Vinyl мы реализовали специальный журнал метаданных, позволяющий легко отслеживать, какой файл принадлежит какому поддереву или поддеревьям. Журнал имеет разрешение .vylog, по формату совместим с .xlog-файлом, и, как и .xlog-файл, автоматически ротируется при каждом чекпоинте. Чтобы избежать пересоздания файлов при split или coalesce, мы ввели промежуточную сущность — slice. Это ссылка на файл, с указанием диапазона значений ключа, которая хранится исключительно в журнале метаданных. Когда число ссылок на файл становится равным нулю, файл удаляется. А когда необходимо произвести split или coalesce, Tarantool создаёт slice-объекты для каждого нового дерева, старые slice объекты удаляет, и записывает эти операции в журнал метаданных. Буквально, журнал метаданных хранит записи вида <id дерева, id слайса> или <id слайса, id файла, min, max>.
Таким образом, непосредственно тяжёлая работа по разбиению дерева на два поддерева, откладывается до compaction и выполняется автоматически.
Огромным преимуществом подхода с разделением всего диапазона ключей на поддиапазоны (ranges) является возможность независимо управлять размером L0, а также процессом dump и compaction для каждого поддерева. В результате эти процессы являются управляемыми и предсказуемыми. Наличие отдельного журнала метаданных также упрощает реализацию таких операций, как truncate и drop — в Vinyl они обрабатываются мгновенно, потому что работают исключительно с журналом метаданных, а удаление мусора выполняется в фоне.
Расширенные возможности Vinyl
Upsert
Ранее я писал лишь о двух операциях, которые хранит LSM-дерево: delete и replace. Давайте рассмотрим, как представлены все остальные. Insert можно представить с помощью replace, нужно лишь предварительно убедиться в отсутствии элемента с таким же ключом. Для выполнения update нам также приходится предварительно считывать старое значение из дерева, так что и эту операцию проще записать в дерево как replace — это ускорит будущие чтения по этому ключу. Кроме того, update должен вернуть новое значение, так что скрытых чтений никак не избежать.
В B-деревьях скрытые чтения почти ничего не стоят: чтобы обновить блок, его в любом случае необходимо прочитать с диска. Для LSM-деревьев идея создания специальной операции обновления, которая не приводила бы к скрытым чтениям, выглядит очень заманчивой.
Такая операция должна содержать как значение по умолчанию, которое нужно вставить, если данных по ключу ещё нет, так и список операций обновления, которые нужно выполнить, если значение существует. На этапе выполнения транзакции Tarantool лишь сохраняет всю операцию в LSM-дереве, а «выполняет» её уже только во время слияния.
К сожалению, если откладывать выполнение операции на этап слияния, хороших опций для обработки ошибок не остаётся. Поэтому Tarantool стремится максимально валидировать операции upsert перед записью в дерево, но некоторые проверки можно выполнить, лишь имея старые данные на руках. Например, если update прибавляет число к строке или удаляет несуществующее поле.
Операция с похожей семантикой присутствует во многих продуктах, в том числе в PostgreSQL и MongoDB. Но во всех из них она представляет собой лишь синтаксический сахар, объединяющий update и replace, не избавляя СУБД от необходимости выполнять скрытые чтения. Я предполагаю, что причиной этого является относительная новизна LSM-деревьев в качестве структур данных для хранения.
Хотя upsert представляет собой очень важную оптимизацию, и при реализации он попил нам немало крови, должен признать, что его применимость ограничена. Если в таблице есть вторичные ключи или триггеры, скрытых чтений не избежать. Ну а если у вас есть сценарии, для которых не нужны вторичные ключи и обновление после завершения транзакции однозначно не приведет к ошибкам — эта операция для вас.
Хотел бы рассказать связанную с этим оператором историю. Vinyl только начинал «взрослеть», и мы впервые запустили upsert в production. Казалось бы, идеальные условия для upsert: огромный набор ключей, текущее время в качестве значения. Операции обновления либо вставляют ключ, либо обновляют текущее время. Операции чтения редкие. Нагрузочные тесты показали отличные результаты.
Тем не менее, после пары дней работы процесс Tarantool начал потреблять 100 % CPU, а производительность системы упала практически до нуля.
Начали копать. Оказалось, что распределение запросов по ключам существенно отличалось от того, что мы видели в тестовом окружении. Оно было… ну очень неравномерное. Буквально, большая часть ключей обновлялась 1-2 раза за сутки, и база для них явно «курила». Но были ключи гораздо более горячие — десятки тысяч обновлений в сутки. Tarantool прекрасно справлялся с этим потоком обновлений. А вот когда по ключу с десятком тысяч upsert’ов происходило чтение, можно было тушить свет. Чтобы вернуть «последнее» значение, Tarantool приходилось каждый раз прочитать и «проиграть» историю из десятков тысяч команд upsert. Проектируя upsert, мы надеялись, что это произойдёт автоматически, во время слияния уровней, но до слияния дело даже не доходило, памяти L0 было предостаточно, и LSM-дерево не спешило выталкивать его на диск.
Решили мы проблему добавлением фонового процесса, осуществляющего «упреждающие» чтения для ключей, по которым накопилось больше нескольких десятков upsert’ов, с последующей заменой всего стэка upsert’ов на прочитанное значение.
Вторичные ключи
Не только для операции update остро стоит проблема оптимизации скрытых чтений. Даже replace при наличии вторичных ключей вынужден читать старое значение: его нужно независимо удалить из вторичных индексов, а вставка нового элемента может этого не сделать, оставив в индексе мусор.
Если вторичные индексы не уникальны, то удаление «мусора» из них также можно перенести в фазу слияния, что мы и делаем в Tarantool.
Транзакции
Append-only природа LSM-дерева позволила нам реализовать в Vinyl полноценные сериализуемые транзакции. Read-only запросы при этом используют старые версии данных и не блокируют запись. Сам менеджер транзакций пока довольно простой: в традиционной классификации он реализует класс MVTO, при этом в конфликте побеждает та транзакция, что завершилась первой. Блокировок и свойственных им дедлоков нет. Как ни странно, это скорее недостаток, чем преимущество: при параллельном выполнении можно повысить количество успешных транзакций, «придержав» некоторые из них в нужный момент на блокировке. Развитие менеджера транзакций в наших ближайших планах. В текущем релизе мы сфокусировались на том, чтобы сделать алгоритм корректным и предсказуемым на 100%. Например, наш менеджер транзакций — один из немногих в NoSQL среде, поддерживающих так называемые gap locks.
Заключение
В этой статье я постарался рассказать, как устроен наш дисковый движок. За время работы над ним проект Tarantool серьёзно повзрослел, сегодня он используется не только в Mail.Ru Group и других интернет-компаниях, также мы продаём и поддерживаем Enterprise-версию сервера в банках, телекоммуникационных компаниях, в компаниях промышленного сектора. Сегодня стабильная версия Tarantool с Vinyl прошла испытание боем как в Mail.Ru Group, так и вне её, и доступна для скачивания на нашем сайте.
Проект Tarantool активно растёт. И мы постоянно ищем единомышленников, чтобы вместе создать СУБД мирового уровня. Если Вы живо интересуетесь темами, затронутыми в этой статье, и наша цель вам кажется важной и интересной — обязательно напишите нам. У нас очень много работы.