Picodata: вторая жизнь In-Memory баз данных
Originally published on Habr
Введение
Привет, я Костя Осипов и занимаюсь разработкой СУБД. На Хабре опубликовано несколько моих статей о MySQL, Tarantool и смежных темах. Я также веду Telegram-канал с инсайтами по управлению базами данных. Сегодня выступаю как основатель Picodata — открытой СУБД и управляющий директор ПАО Arenadata по исследованиям и разработке. Это вольный пересказ доклада на HighLoad о будущем СУБД и месте резидентных баз данных в современных архитектурах.

Бэкграунд: эволюция аппаратного обеспечения и СУБД
Когда десять лет назад предсказывали тренды СУБД, становится смешно вспомнить неудачные прогнозы. Прогнозировали снижение стоимости оперативной памяти, её увеличение, появление энергонезависимой памяти, исчезновение дисков и SSD. Активно говорили о переходе на облачные, горизонтально масштабируемые системы с полной контейнеризацией.
Главной идеей эпохи Webscale стало горизонтальное масштабирование. Типичная СУБД будущего виделась как горизонтально масштабируемая, облачная, резидентная система. Но будущее оказалось совсем другим — и оно уже наступило.

Современное оборудование
Компания Pascari анонсировала жёсткий диск на 122 TB. Аналогичные диски планирует выпускать Solidigm. Важны не только объёмы, но и производительность: один диск обеспечивает 3 млн IOPS на чтение и 35 тыс IOPS на запись. Восемь таких дисков содержат более петабайта данных, а дополненные процессорами на 96–128 ядер (например, AMD EPYC 9xxxx), дают мини-дата-центр в двухъюнитовом сервере. Заполнение диска данными требует 12+ часов.
Если большие накопители столь доступны, нужно ли горизонтальное масштабирование? Многие современные СУБД, оптимизированные под многопоточность и большие объёмы памяти (OrioleDB как форк PostgreSQL), показывают результаты, сравнимые с многомашинными кластерами.
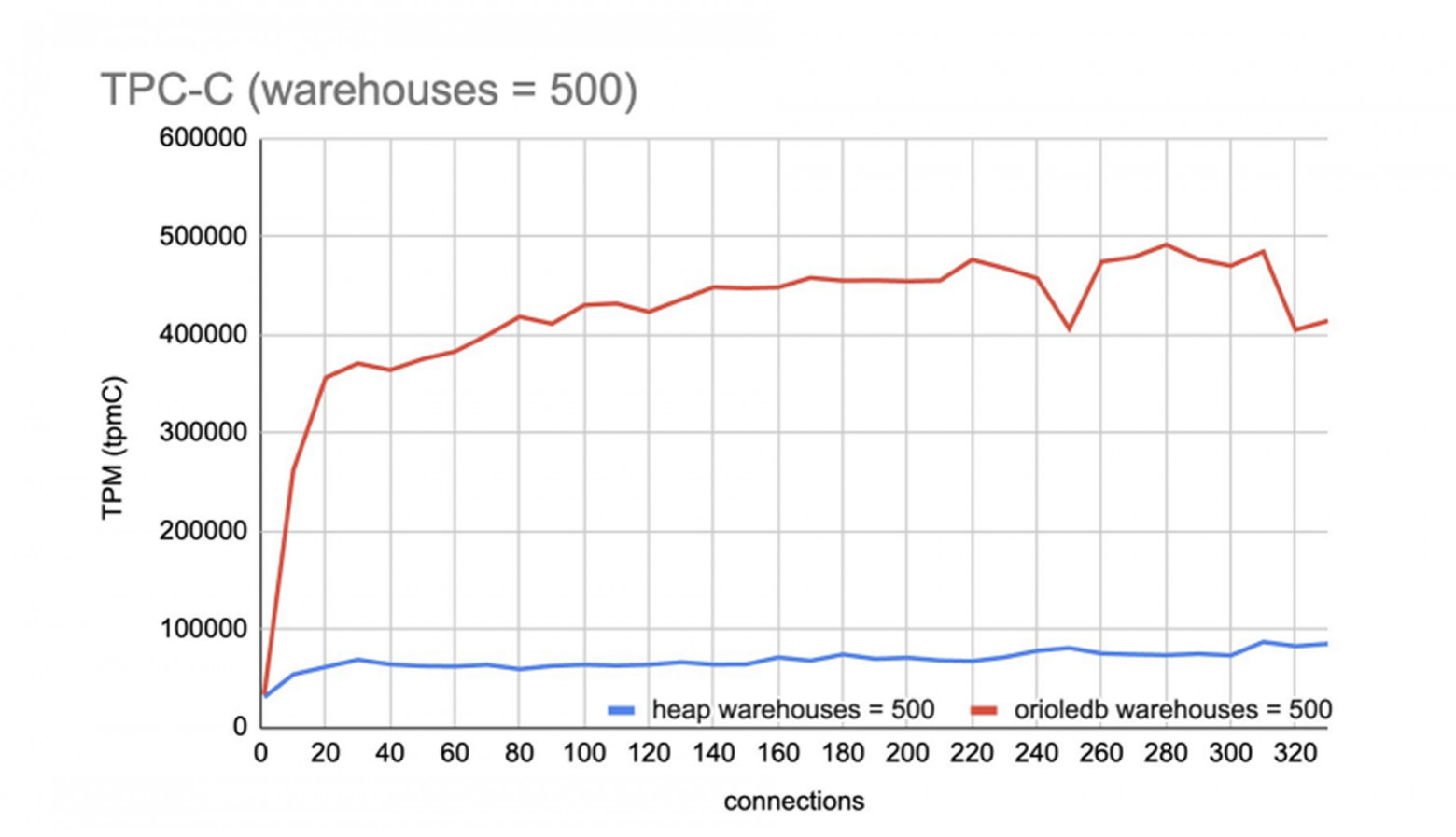
Также существуют горизонтально масштабируемые системы, извлекающие из одного узла на порядок большую скорость. ScyllaDB на трёх средних узлах (32 ядра, 3,5 Ghz, 256 GB RAM) с фактором репликации 3 показывает 500 000 запросов в секунду.
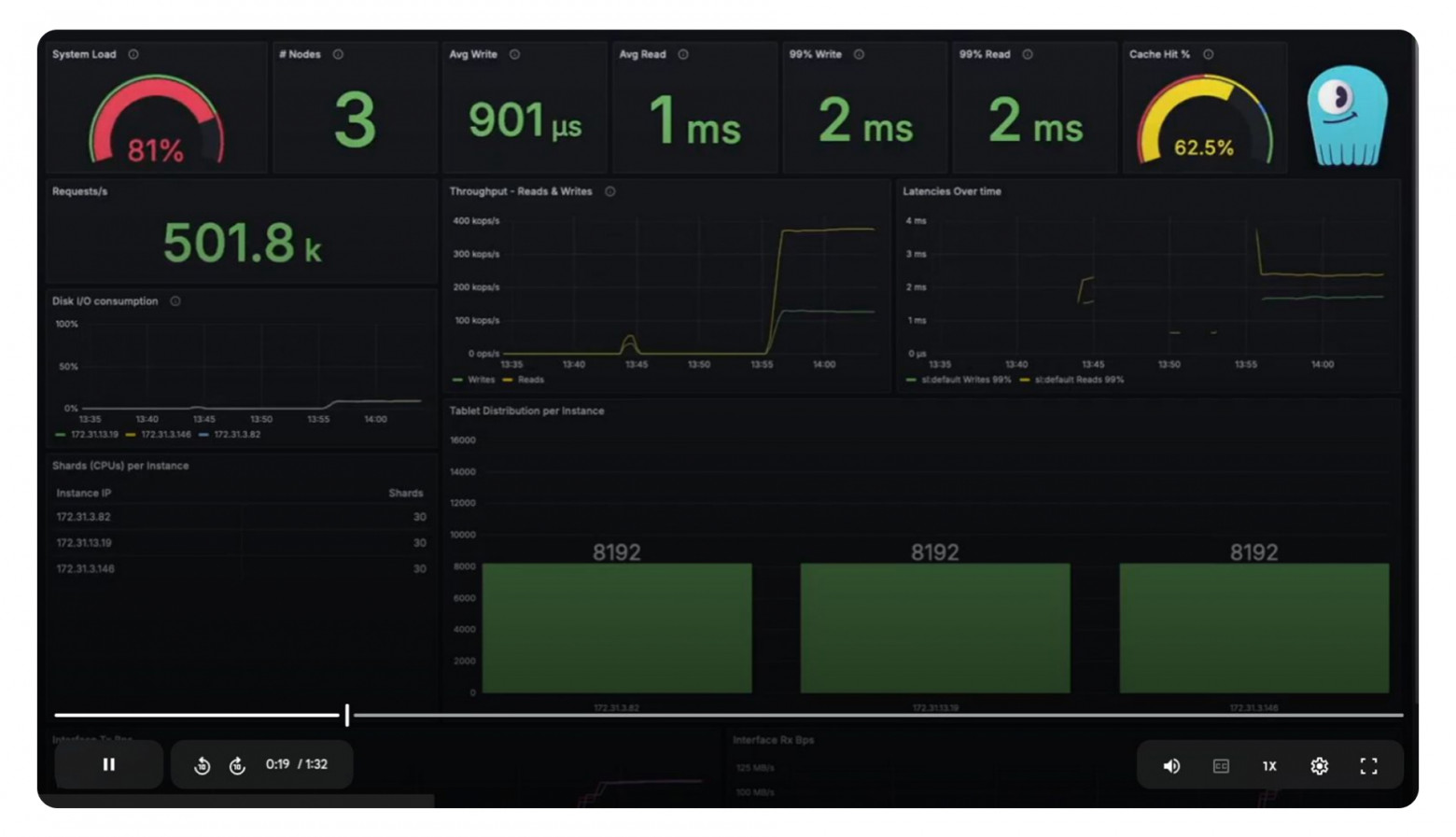
Вывод: противопоставление горизонтальной и вертикальной масштабируемости менее важно, чем внутреннее устройство СУБД, адекватное современному оборудованию.
Тренды в мире СУБД
1. Разделение compute и storage
Идея разделения вычислений и хранения противоречит принципу локальности данных (девиз Tarantool: “bring compute close to storage”), но экономически оправдана в облачах. Масштабировать вычисления проще, хранение-как-сервис подешевело. С ростом данных приоритет смещается на снижение стоимости хранения, даже в ущерб производительности.
Кластерные СУБД отстают от реальности: масштабирование кластера, работа в Kubernetes считаются “особенными” операциями. Лидеры тренда — Trino, DuckDB с MotherDuck, Neon; есть контртренд типа Turso. В 5–10 лет эволюция вернёт конвергентные архитектуры, так как аналитика требует минимальной задержки и near-real-time-анализа.
2. Закрытие исходного кода и облака

Вендоры переходят на проприетарные лицензии: MongoDB, Elasticsearch, ScyllaDB, Greenplum, CockroachDB, Timescale. Одни защищаются от облачных провайдеров, другие строят модель DBaaS. Деглобализация наносит удар по Open Source: гонения разработчиков, глубокие форки в Китае, консервативность мейнтейнеров.
Фрагментация лицензий: AGPL, BSL, SSPL. Переиспользование кода между non-free-лицензиями невозможно, что фрагментирует ресурсы сообщества.
Привязка к облакам: многие СУБД поставляются как managed service и теряют возможности вне этого окружения.
На этом фоне по-настоящему открытыми останутся только платформенные игроки — те, кто предлагает экосистему решений для работы с данными, а не одну конкретную СУБД.
3. Специализация и модульность
Тренд polyglot persistence (15 лет развития от Cassandra и Kafka) не привёл к консолидации. Напротив, появляются всё новые специализированные СУБД для AI, аналитики, встраиваемых решений.
Новый тренд: модульность баз данных. 10 лет назад “строительные блоки” считались редкостью: RocksDB, SQLite, H2. Их преимущество — не разрабатывать всё с нуля. RocksDB используется в MySQL, ArangoDB, TiDB, Yugabyte; FoundationDB построен на SQLite. Ключевые части (оптимизатор запросов) были немодульными.
Ситуация меняется:
- Apache DataFusion Kernel — аналитический оптимизатор запросов для разных продуктов
- etcd-raft — модуль репликации в etcd и CockroachDB
- cassandra-accord — алгоритм транзакций Cassandra как отдельный проект
- DuckDB применима далеко не только в DuckDB Labs
- Turso переписал SQLite на Rust для Rust-экосистемы
- Dremio/Apache Iceberg переопределяют работу с холодными данными
Изменяется бизнес-ландшафт: CIO/CDO ставят на экосистему целиком (Amazon, Google, в России — Sber Platform V, Yandex, Arenadata), а разработчикам предоставляют выбор инструмента в пределах экосистемы.
Место резидентных СУБД
Обзор выше обосновывает видение Picodata. Большие быстрые диски означают, что скорость доступа к диску не может быть фактором выбора резидентной СУБД. Закрытие вендоров требует удобного инструмента для разработчиков. Тренд разделения compute/storage и эластичность означают, что добавление/удаление узлов и работа в Kubernetes должны быть рутиной, не влияя на производительность и troubleshooting.
Почему in-memory?
Резидентные СУБД ускоряют не просто размещением в памяти. Достаточно было бы дать PostgreSQL больше кэша. Кратное ускорение даёт:
- Специализированные структуры данных
- Менеджеры транзакций
- Управление многопоточностью
- Архитектурный подход shard-per-core: данные по ядрам, без блокировок и конкуренции
Нужны ли эти усилия, если диски достаточно быстры?
Цифры: SSD даёт 10–20 микросекунд, RAM — 10–20 наносекунд. Хотя диски в 100 раз быстрее, чем HDD, разница с памятью три порядка. Но между чтением и пользователем стоит ОС и сеть:
- Накладные расходы ОС: ~50 микросекунд (квант планировщика Linux)
- Передача в дата-центре: ~200–300 микросекунд
Сам диск/память становится несущественным в микросервисной архитектуре.
Размещение логики внутри СУБД
Что если разместить логику приложений внутри СУБД в виде плагина/хранимой процедуры? Вернёмся к ускорению на 3–5 порядков от прямого доступа.
Сценарии оправданности:
- Интеграция данных в высокодоступную витрину (личный кабинет федерального масштаба)
- Тарификация, высокочастотная торговля, real-time bidding, таргетинг, скоринг
- Компрессия IoT данных на лету, промышленные платформы
- Ускорение ERP, расчёты себестоимости, отчётность, зарплата для вертикально интегрированных компаний
“Чуть быстрее” = “существенно выигрываем в бизнесе”.
Вертикально масштабируемые СУБД набирают популярность с ростом мощности серверов; IMDG подход не потерял релевантность.
Хранимые процедуры и микросервисы
В высоконагруженных проектах хранимые процедуры — антипаттерн. Близкий родственник SQL/PSM (стандартный PL/SQL) — язык ADA (1980). Дело не в архаичном синтаксисе, а в:
Сложность управления разработкой
В микросервисах/DevOps код в системе контроля версий, stateless-контейнеры, CI/CD, A/B-тестирование. Аналогов в хранимых процедурах нет (или о них никто не говорит).
Сложность отладки и тестирования
Как запустить интерактивный отладчик, изолировать ошибку, избежать hot spots на production? Нужны функциональные и performance-тесты. Тестирование миграций схемы и логики СУБД не распространено; проще schema-less JSON (теряется производительность и качество).
Сложность обновлений
Как консистентно обновить логику в распределённом кластере без простоя? Flyway/Liquibase работают со схемой, но не с логикой распределённой базы. Версии схемы и кода должны совпадать; откат может быть невозможен.
Picodata предлагает инструменты и методы работы с этими ограничениями.
Домены отказа, тиры и Rust-плагины
Архитектура кластера
Задача кластерной СУБД — разделить данные между узлами, представляя их единым целым, используя мощности всех узлов.
Подход:
-
Шарды — разделение данных между процессами СУБД на ядрах. Каждый шард хранит данные всех таблиц; распределение определяется при создании.
-
Репликация — при отказоустойчивости шард обслуживают несколько процессов (инстансов/узлов) в разных дата-центрах, копируя данные. Набор инстансов одного шарда — репликасет.
-
Бакеты — вторичное разбиение внутри шарда. Шард — десятки/сотни GB, бакет — десятки MB. Позволяет гибко балансировать нагрузку, перемещать части данных.
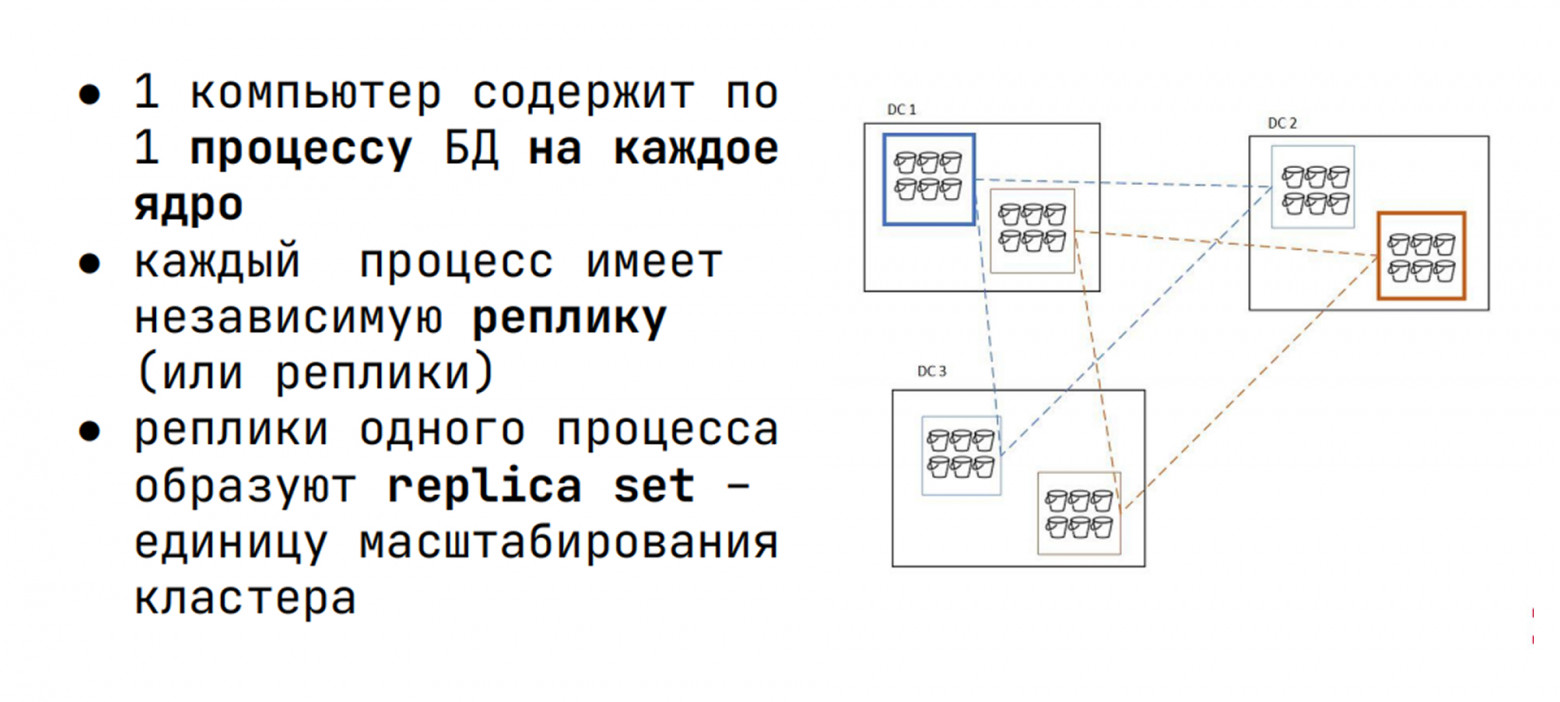
Подход масштабируется горизонтально и вертикально: множество ядер = множество СУБД-процессов, максимизируя утилизацию.
Упрощение для операторов
Когда управление кластером требует когнитивной сложности, это скрыто от пользователя. Все управление и балансировка автоматичны.
Шаги:
-
Встроенный state provider — аналог etcd, часть каждого узла, хранит состояние в системных таблицах. Метаданные кластера консистентно реплицируются (используется raft-rs). Позволяет восстановить топологию/схему при аварии. Встроенная репликация быстрее, облегчает развёртывание больших кластеров.
-
Домены отказа — концепция для описания конфигурации. Домен — пара ключ/значение, описывающая расположение узла (например,
datacenter: msk). DBA указывает только расположение; кластер-менеджер копирует состояние, определяет репликацию, перераспределяет данные.

Управление кластером
Две операции: добавить инстанс (add) или удалить (expel). Все СУБД-процессы доступны для запросов, автоматически маршрутизируя вычисления к узлу с данными. Восстановление и перебалансировка — автоматические.
Домен отказа необязательно описывает дата-центр; может быть сервером или стойкой.
Пример: два сервера в одном DC, 100% зарезервированные копии.
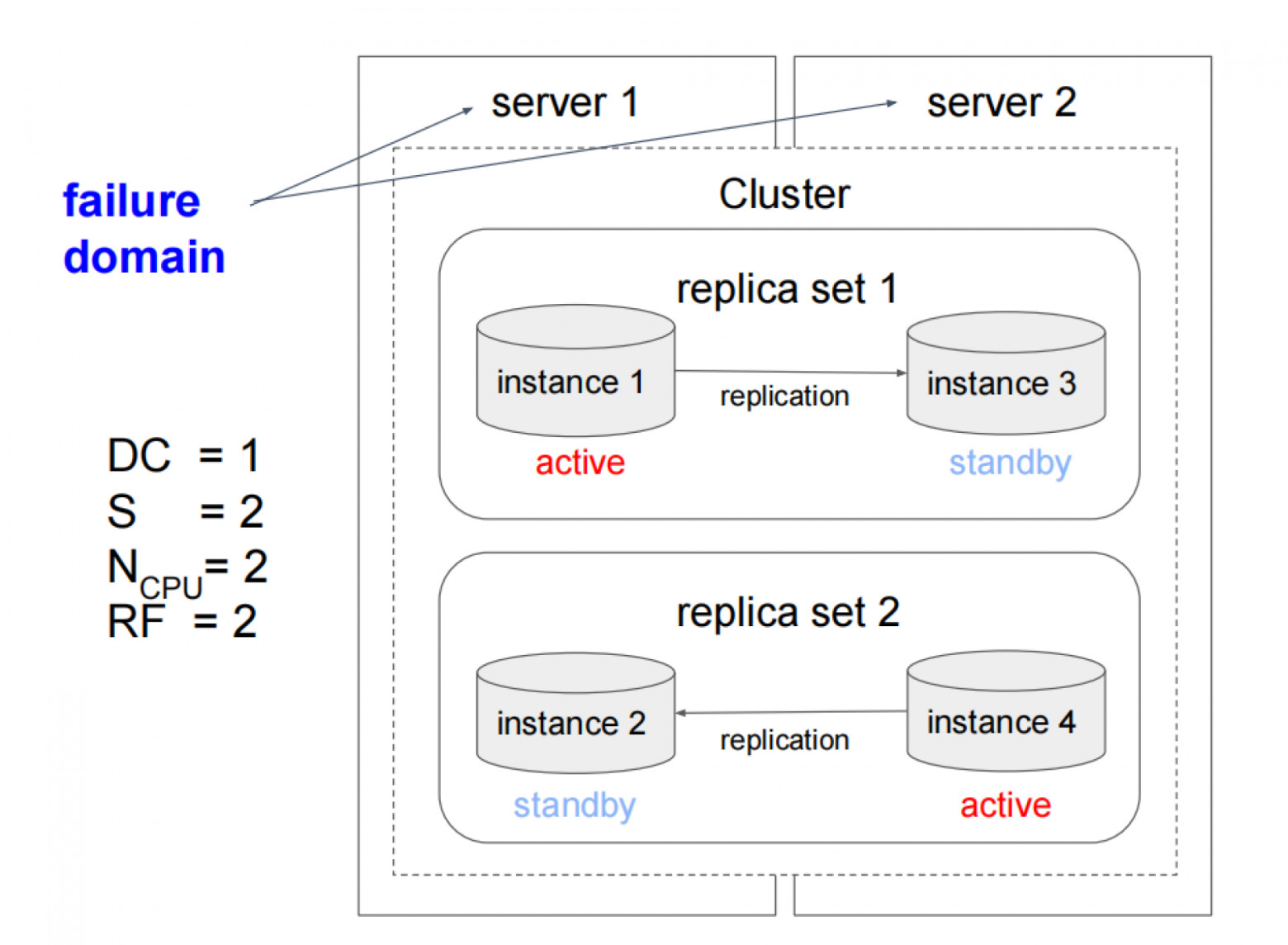
- Picodata автоматически распределяет реплики между доменами
- При падении машины или DC система работает (при нужном числе реплик)
Тиры
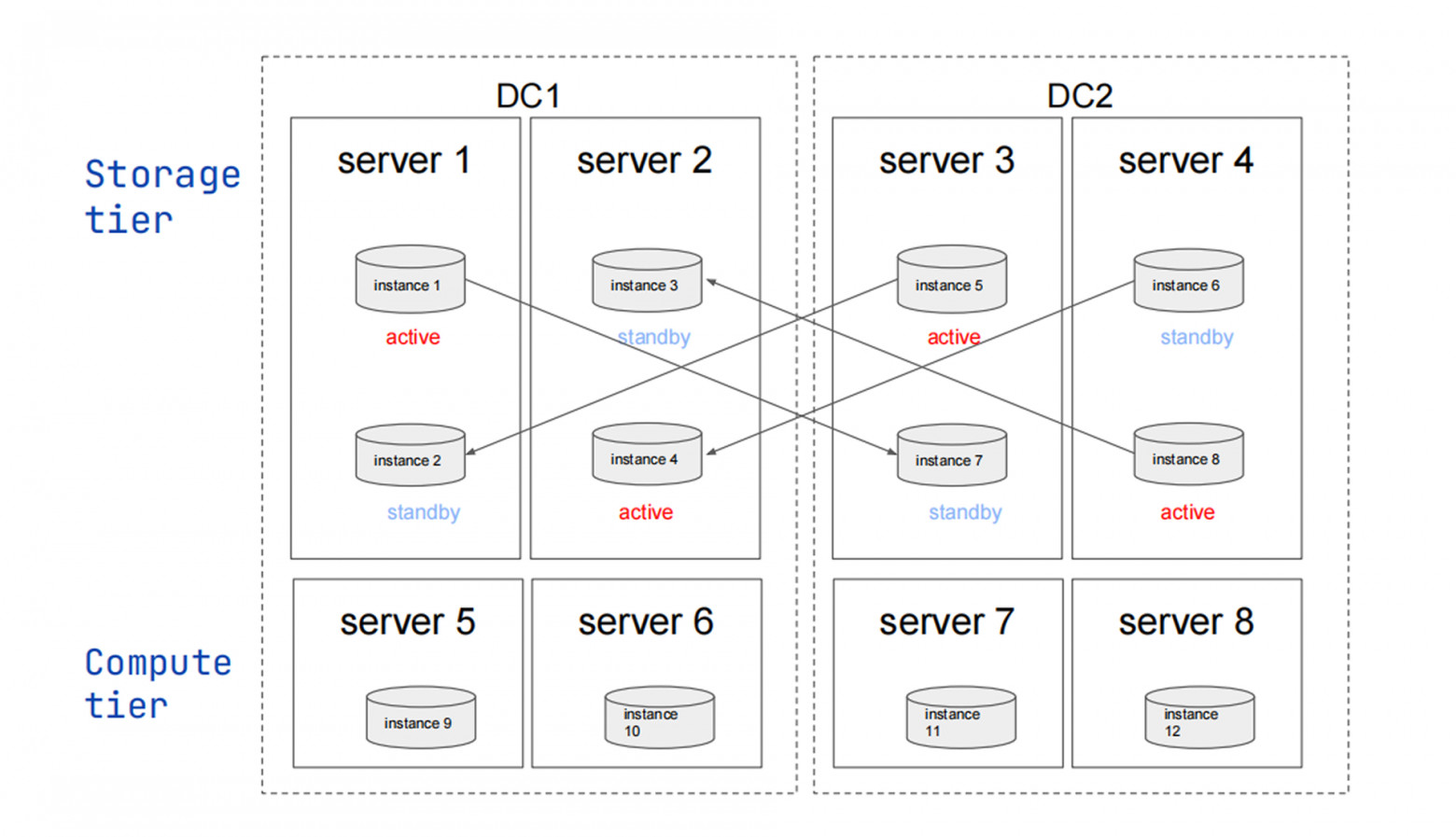
Типовые кластеры — одинаковые инстансы, одна задача. Сложные сценарии требуют разных типов.
Сценарии:
- Часть ресурсов для вычислений/балансировки
- Развёртывание 1+1 или 2+2: два DC, при падении одного данные остаются доступны на запись в другом (без третьего DC)
- Разные данные с разным уровнем надёжности
- Данные > RAM; для некоторых таблиц нужен движок vinyl
Каждый инстанс принадлежит одному домену отказа и одному тиру. Вместе они описывают топологии: симметричные (каждый домен содержит все тиры) или асимметричные (арбитр в выделенном домене, не хранит данные, обеспечивает 100% доступность).
Управление кодом: Blue-Green Deploy для плагинов
Домены/тиры упрощают управление, но не помогают версионировать хранимые процедуры. Они — фундамент отказоустойчивого кластера, но для blue/green-развёртывания нужны два кластера, соединённые репликацией.
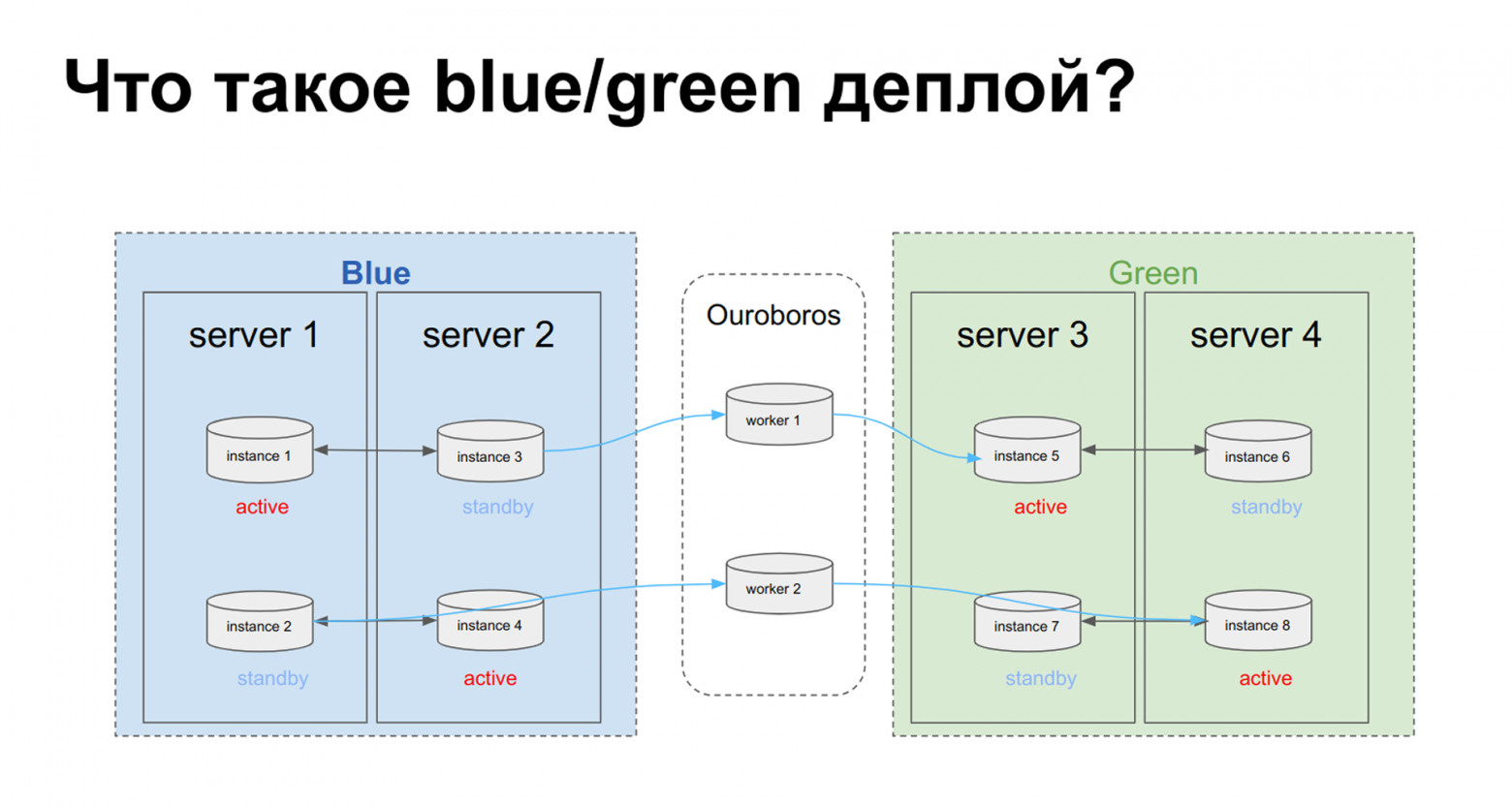
Зачем Blue-Green Deploy?
Blue-Green Deploy — практика параллельного разворачивания новой версии, live-тестирования, откатывания без простоя. Picodata распространяет принцип на код в СУБД.
Почему:
-
Кластерная среда усложняет обновления — в обычной СУБД обновление на одном сервере; в распределённой всё должно обновляться согласованно на всех узлах (избежать рассинхронизации версий схемы/кода).
-
“Аккуратная” миграция — транзакционные данные привязаны к структурам, меняющимся с версией. Сначала мигрировать схему/данные, затем включать новую логику.
-
Безопасный откат — новая версия может содержать ошибки, вести себя непредсказуемо. Blue-Green даёт понятные шаги откатки (Rollback).
Picodata использует Blue-Green не только для плагинов, но для любой пользовательской логики. Процесс:
- Миграция схемы (SQL)
- Конфигурация новой версии плагина
- Включение нового кода во всём кластере
- При ошибке — откат всей операции
Компоненты Blue-Green Deploy
1. Версия плагина
У каждого плагина версия (1.0, 1.1); в кластере не может быть >2 разных версий одного плагина (Blue — старая, Green — новая).
2. Манифест (manifest)
Файл с описанием плагина, сборки, функционала, SQL-миграций:
name: weather_cache
description: That one is created as an example of Picodata's plugin
version: 0.1.0
services:
- name: weather_service
default_configuration:
openweather_timeout: 5
migration: migrations/0001_weather.db
3. Миграции (up / down)
SQL-файлы с секциями:
-- pico.UP
CREATE TABLE "weather" (
id UUID NOT NULL,
latitude NUMBER NOT NULL,
longitude NUMBER NOT NULL,
temperature NUMBER NOT NULL,
PRIMARY KEY (id)
)
USING memtx
DISTRIBUTED BY (latitude, longitude);
-- pico.DOWN
DROP TABLE "weather";
up— при установке/обновлении (новые таблицы/поля)down— при откате (убрать изменения)
4. Конфигурация (configuration)
После установки задаются параметры (ключи доступа, настройки соединений). Хранится консистентно во всём кластере, не на одной ноде. Каждая версия — свой набор параметров, менять независимо. При установке новой версии начальные значения из старой версии и манифеста.
5. Enable / Disable
После миграции/настройки — “включить” (enable) новую версию или “выключить” (disable) старую. Синхронно на всех нодах.
Процесс обновления плагина
-
Ставим/загружаем новую версию — Picodata получает манифест, собирает/распаковывает плагин, регистрирует как “возможный”.
-
Выполняем миграцию — Запускается
up-скрипт, меняет схему. Атомарно на всех узлах. Успех — сохраняем. Ошибка — откат + лог. -
Настраиваем и привязываем к тирам — Указываем, на каких тирах/узлах работает плагин, параметры. Конфигурация реплицируется.
-
Enable новой версии — Система включает новую версию, она обслуживает запросы. Старая существует до уверенности.
-
Disable/Remove старой версии — Отключаем старую. Если проблема — откат (rollback), запуск
down, возврат к коду.
Ouroboros и асинхронная репликация
Для отладки новых версий без влияния на production реализован ouroboros — плагин логической асинхронной репликации между кластерами Picodata. Позволяет:
- Создать копию кластера
- Реплицировать все данные или выборочно (только таблицы)
- Для сложных приложений — только таблицу входящих запросов
- Выполнить новую версию логики на резервном кластере независимо
- После отладки — переключить трафик на резерв (swap blue/green) или установить обновление на основном
Модульность и доставка кода
Picodata использует Rust для расширений, модульную архитектуру языка. Внутри плагина — множество модулей/зависимостей; при создании бандла — один бинарный файл.
Несколько плагинов взаимодействуют через общие данные (таблицы), не код. Защищает production от карнавала несовместимых версий зависимостей. Аналогия — go build в Go.
Создана утилита pike, автоматизирующая разработку и поставку плагина в кластер.
Все инструменты и методы вместе делают размещение логики рядом с данными управляемым.
SQL в Picodata
Плагины имели бы ограниченный функционал без кластерного SQL. Picodata сделала SQL максимально эффективным.
Протокол и инструменты
Основной протокол — PostgreSQL. Работают многие инструменты экосистемы PostgreSQL: psql, DBeaver; многие драйверы.
Проблема коллокации
В CockroachDB/TiDB данные в едином пространстве key-value (RocksDB, TiKV); SQL поверх NoSQL. Удобно для автошардирования, но порождает ненужные перемещения данных между узлами при JOIN.
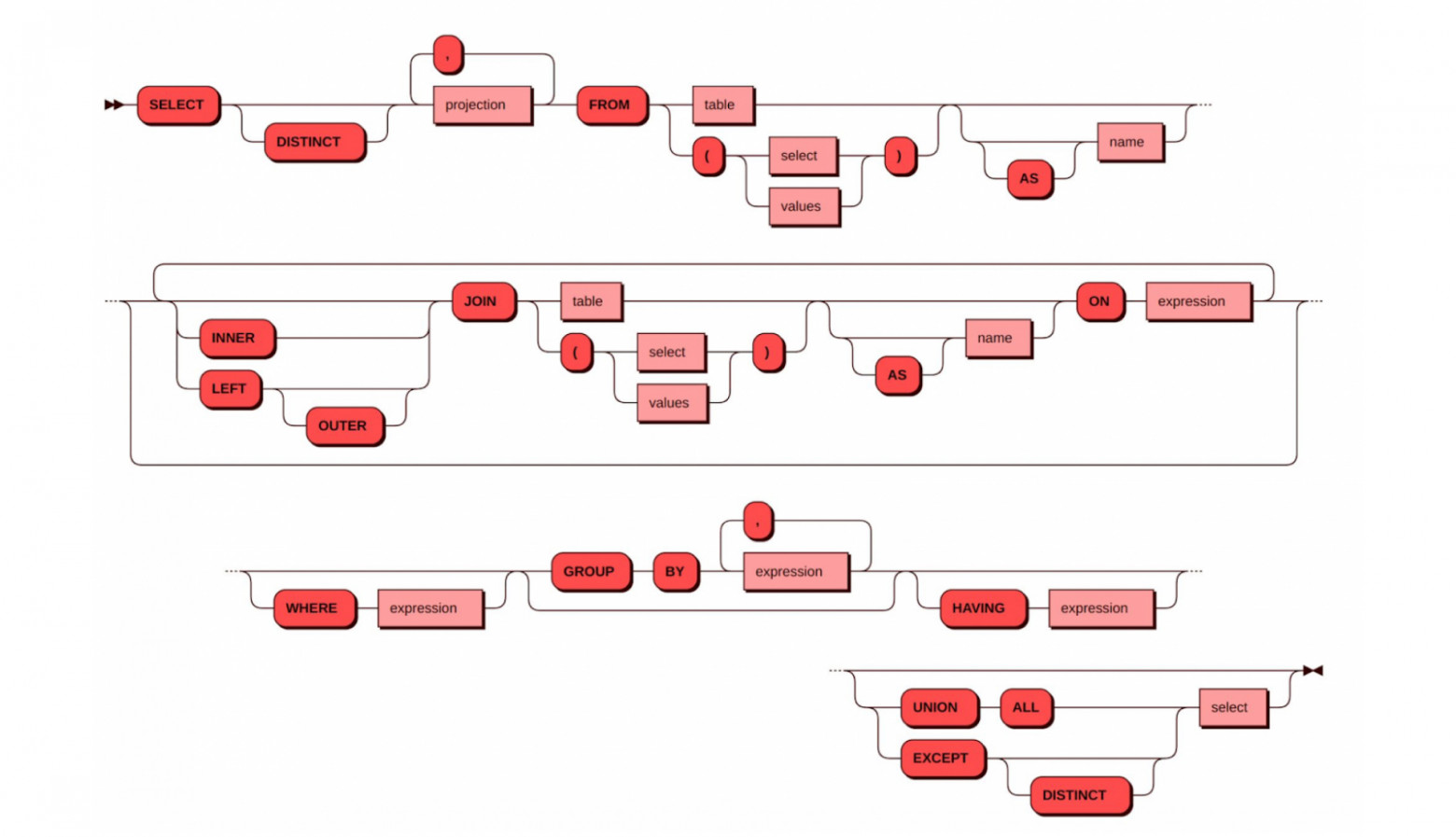
Picodata передаёт управление коллокацией в руки разработчика.
При создании схемы для сценариев клиента — все данные одного клиента на одном узле, глобальные справочники идентичны на всех узлах. Результаты:
- Большинство бизнес-сценариев без перемещения между узлами
- Большинство транзакций локально на одном узле (нет конфликтов, блокировок)
- Нагрузку можно распараллелить
Коллокация по ключу
По умолчанию данные разбиваются между узлами по ключу распределения:
CREATE TABLE ITEM (
I_ID INTEGER NOT NULL,
I_IM_ID INTEGER,
I_NAME VARCHAR(24),
I_PRICE NUMBER,
I_DATA VARCHAR(50),
PRIMARY KEY (I_ID)
)
USING MEMTX DISTRIBUTED BY (I_ID);
Управление коллокацией — расширение SQL DISTRIBUTED BY. Синтаксис из Greenplum. DISTRIBUTED BY (client_id) для таблиц orders, payments, sessions — все записи клиента на одном узле.
Глобальные таблицы
Для данных на всех узлах — глобальное (global) распределение:
CREATE TABLE WAREHOUSE (
W_ID INTEGER NOT NULL,
W_NAME VARCHAR(10) NOT NULL,
W_TAX DOUBLE,
W_YTD DOUBLE,
PRIMARY KEY (W_ID)
)
USING MEMTX DISTRIBUTED GLOBALLY;
В аналитике глобальные таблицы для “small dimension table”: факты распределены, измерения глобальны.
Итоги
Picodata — попытка переосмыслить in-memory-базы в эпоху, когда современное “железо” (миллионы IOPS, сотни TB на сервере) делает горизонтальное масштабирование не всегда оправданным. Цель — удобный инструмент для разработчиков высоконагруженных проектов.
В эпоху смены лицензий и закрытия возможностей Picodata:
- Сохранила открытую лицензию BSD
- Продолжает инвестиции в Open Source
- Для корпоративных клиентов — версия с сертификатом ФСТЭК, коммерческие расширения: промышленные данные, миграция с проприетарных СУБД, замена Redis/Cassandra
Развитие: каждый день появляются возможности. Версия 25.1 реализует оконные функции. Среднесрочные планы: материализованные представления, стоимостный оптимизатор, колоночное хранение.
Если in-memory-СУБД заместят классические системы (PostgreSQL, Oracle), Picodata будет в локомотиве этого движения.