Хранение данных на Виниле
Originally published on Habr
В 2016-м я выступил на Highload с докладом про Vinyl, движок для хранения данных на диске в Tarantool. С тех пор мы добавили много новых возможностей, но хранение данных на диске — такая объемная тема, что основы, о которых идет речь в этой статье, совсем не изменились.

Почему мы написали новый движок?
Как известно, Tarantool — транзакционная, персистентная СУБД, которая хранит 100% данных в оперативной памяти. Основные преимущества хранения в оперативной памяти — это скорость работы и простота использования: базу данных не нужно тюнить, тем не менее, производительность остаётся стабильно высокой.
Несколько лет назад возникла идея расширить продукт классической технологией хранения, когда в памяти находится только кэш, а основной объём находится на диске. Решили, что движок можно выбирать независимо для каждой таблицы, как в MySQL, но с поддержкой транзакций с самого начала.
Рассматривались готовые библиотеки: RocksDB, WiredTiger, ForestDB, NestDB, LMDB. Однако все они предполагают многопоточный доступ с комплексными примитивами синхронизации.
Tarantool использует архитектуру на основе акторов. Обработка транзакций в выделенном потоке позволяет избежать блокировок и накладных расходов, поглощающих до 80% процессорного времени многопоточных СУБД. Проектирование с прицелом на кооперативную многозадачность обеспечило лучший результат.
Процесс Tarantool состоит из фиксированного количества «ролевых» потоков.
Алгоритм
Существует два поколения решений: B-деревья (MySQL, PostgreSQL, Oracle) и LSM-деревья (Cassandra, MongoDB, CockroachDB). B-деревья считались эффективнее для чтения, LSM — для записи. С распространением SSD преимущества LSM стали очевидны для большинства сценариев.
Проблемы B-деревьев
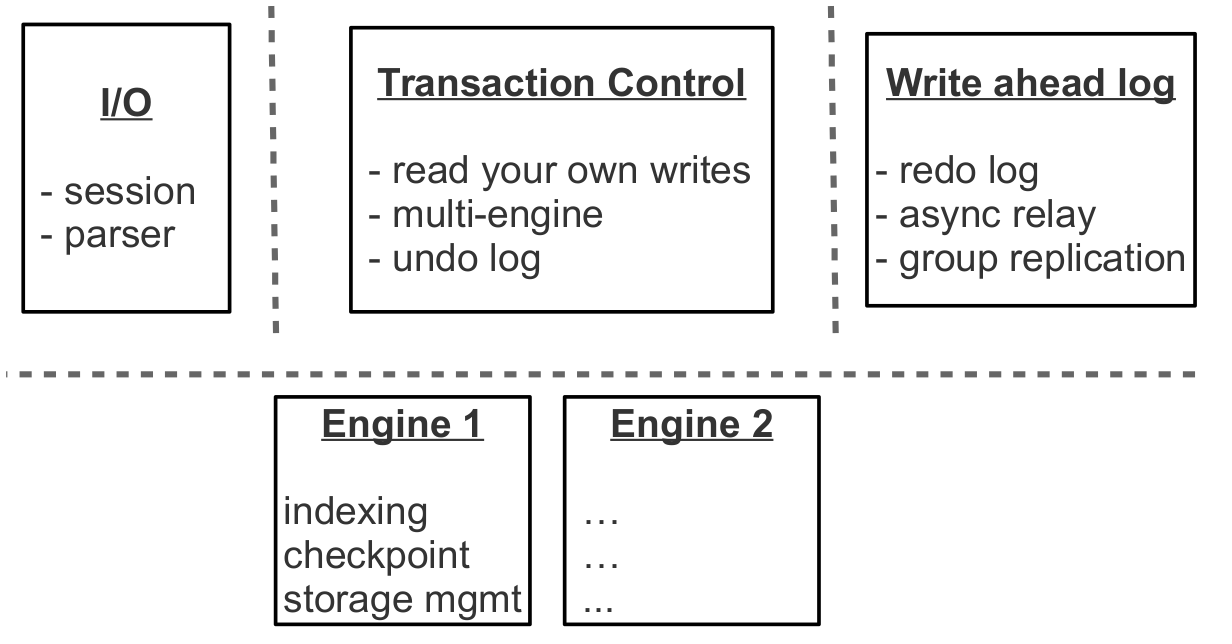
B-дерево — сбалансированное дерево из блоков с отсортированными ключ-значение парами. При поиске алгоритм читает log_B(N) блоков, где N — количество элементов.
Пример: дерево из 100 млн элементов по 100 байт, размер блока 4096 байт. В блоке размещается ~40 элементов. Дерево содержит ~2,57 млн блоков, 5 уровней. Все уровни кроме последнего (~10 ГБ) попадают в кэш.
Проблема записи: обновление одного элемента требует чтения блока, изменения 100 байт из 4096 и записи полного блока. Получается 40-кратное увеличение записываемого объёма!
Это явление называется write amplification (коэффициент — отношение фактически записанных данных к необходимым). Read amplification — аналогичное явление для чтений.
Ключевое отличие LSM

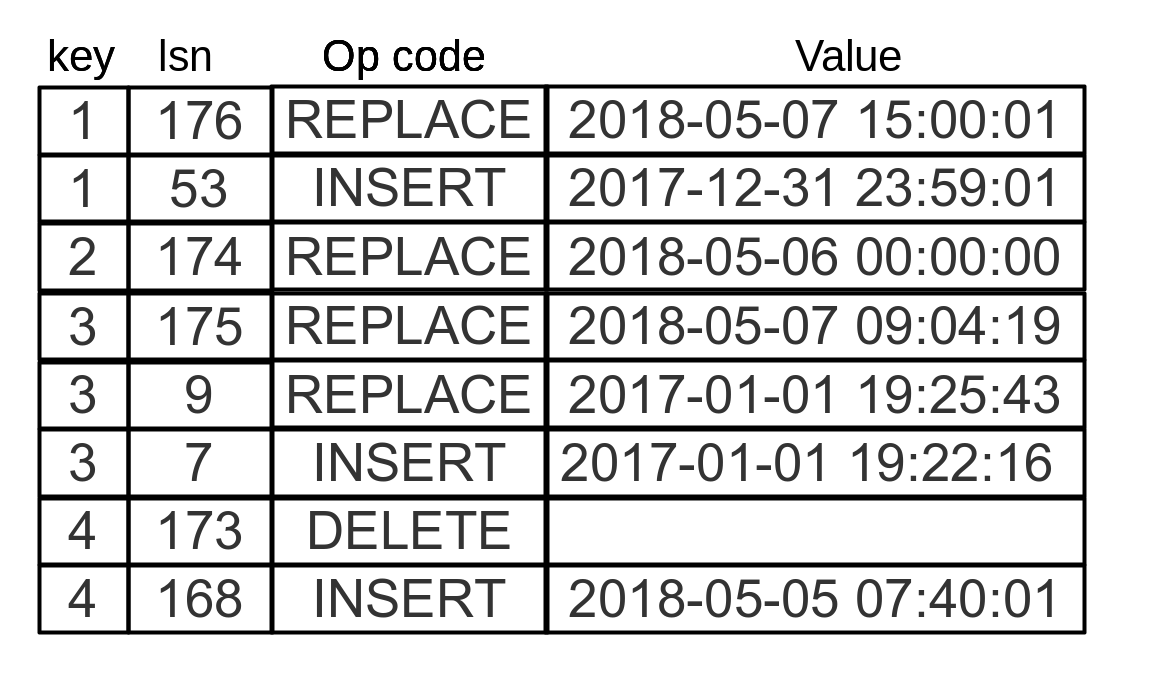
LSM хранит не данные, а операции: вставки и удаления. Элемент содержит:
- Ключ и значение
- Код операции (REPLACE или DELETE)
- Log sequence number (LSN) — монотонно возрастающий порядковый номер
Дерево упорядочено сначала по возрастанию ключа, затем по убыванию LSN.
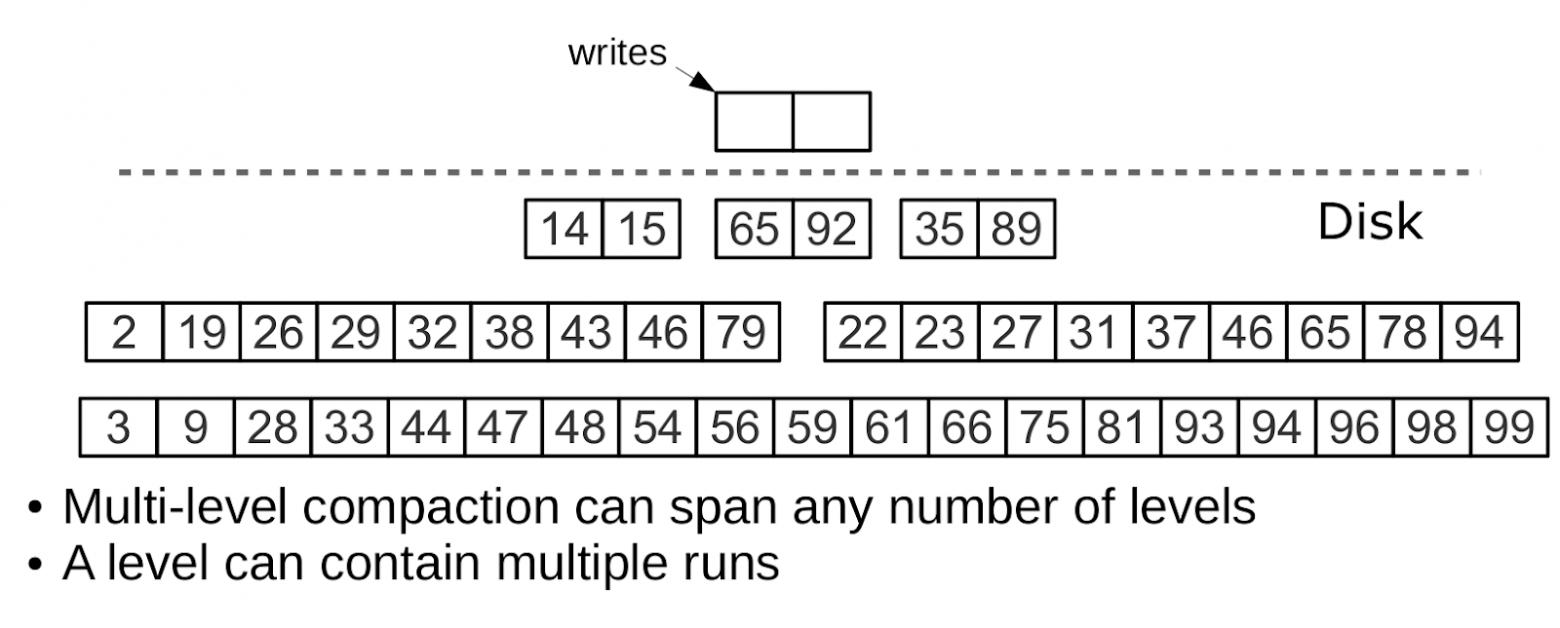
Устройство одного уровня
Наполнение LSM дерева
L0 (level zero) — часть дерева в оперативной памяти. Размер задаётся опцией vinyl_memory. Элементы добавляются в L0 как в обычную структуру данных (Tarantool использует B+*-tree).
Когда L0 переполняется, выполняется dump — запись L0 в файл на диск и освобождение памяти.
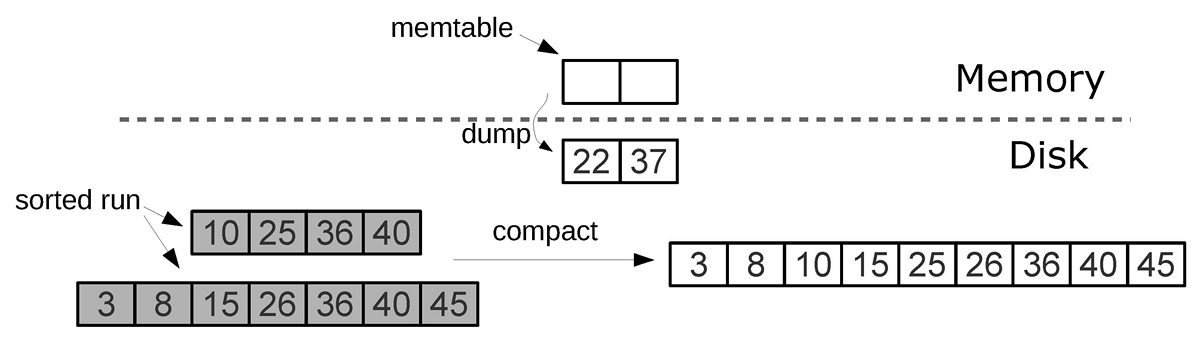
Все дампы образуют последовательность на диске, упорядоченную по LSN. Более новые файлы находятся вверху пирамиды. При слиянии (compaction/merge) несколько старых файлов объединяются в новый. Если встречаются две версии одного ключа, сохраняется только новая. Если ключ был вставлен, а потом удалён, обе операции исключаются.
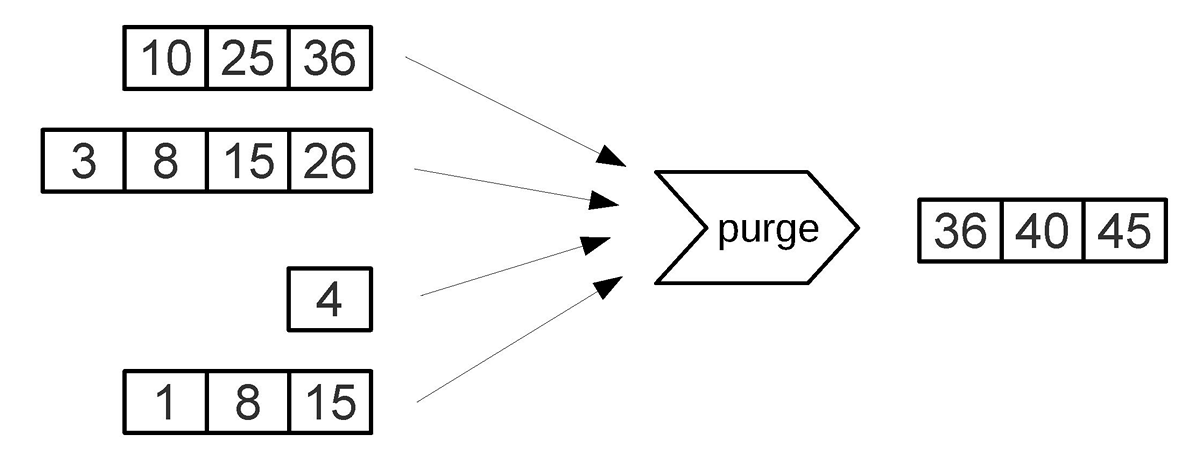
Управление формой LSM-дерева
Соотношение размеров файлов на разных уровнях (level_size_ratio) определяет форму пирамиды:
- Большое соотношение → меньше уровней → быстрее поиск, но больше затрат на compaction
- Маленькое соотношение → больше уровней → больше поисков, но реже compaction
Write amplification описывается формулой: x×ln(N/L0)/ln(x), где x — соотношение размеров, N — суммарный размер, L0 — размер памяти.
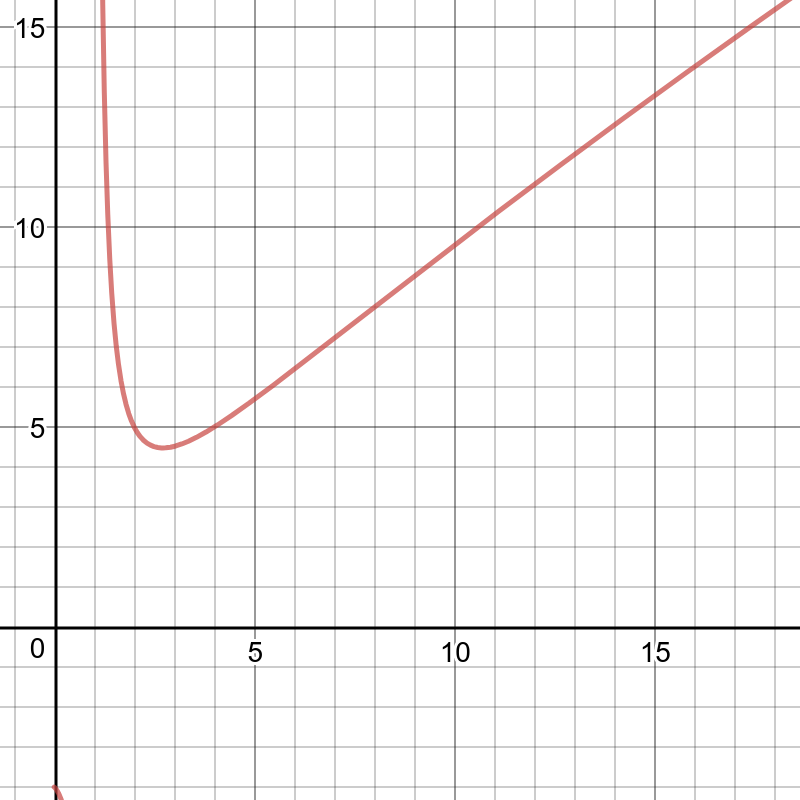
Для канонического примера (100 млн элементов, 256 МБ памяти, vinyl_level_size_ratio=3.5, run_count_per_level=2):
- Write amplification ≈ 13
- Read amplification может достигать 150
Поиск
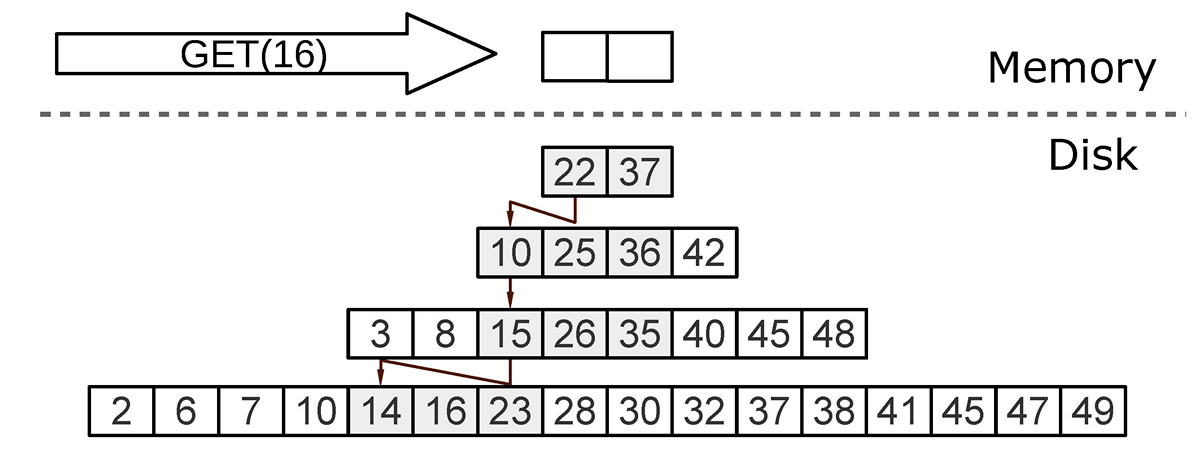
Необходимо найти последнюю операцию с ключом. Если это DELETE — элемент отсутствует. Если REPLACE — получено значение. В худшем случае (элемент не существует) поиск проходит все уровни L0-Lk.
Частый сценарий: вставка в уникальный индекс требует проверки отсутствия дубликатов. Это приводит к полному поиску. Для оптимизации используются Bloom-фильтры.
Поиск по диапазону
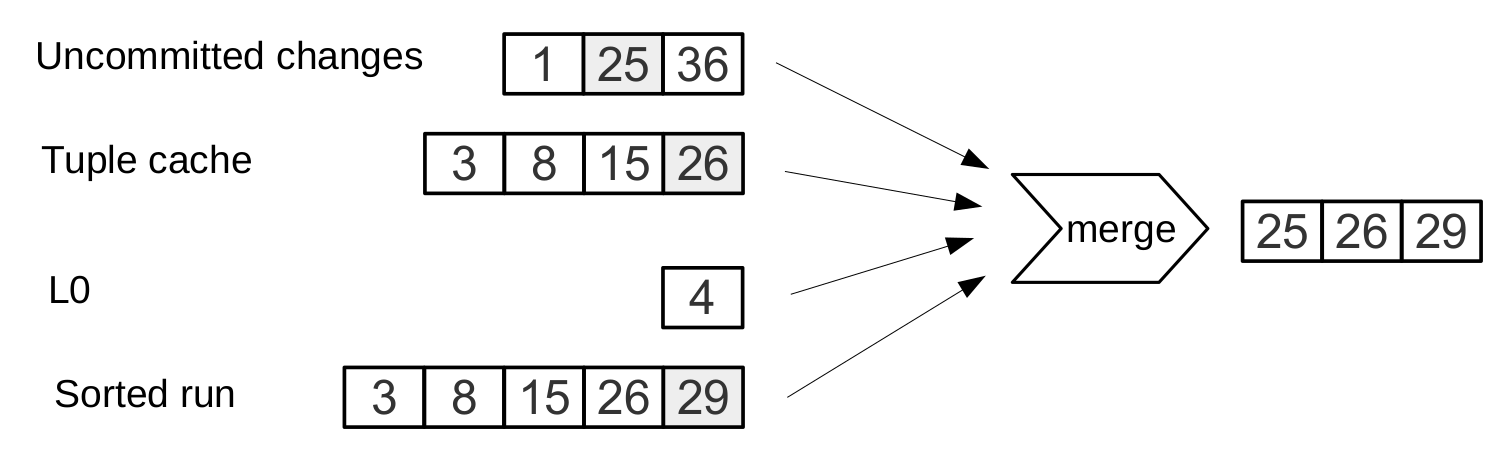
Поиск по диапазону [24,30)
Поиск всех значений в диапазоне требует просмотра всех уровней дерева. Из всех источников выбирается ключ с максимальным LSN, остальные операции отбрасываются.
Удаление
Зачем хранить удаления (tombstones)?
- При поиске они сигнализируют об отсутствии значения
- При слиянии очищают дерево от “мусорных” записей
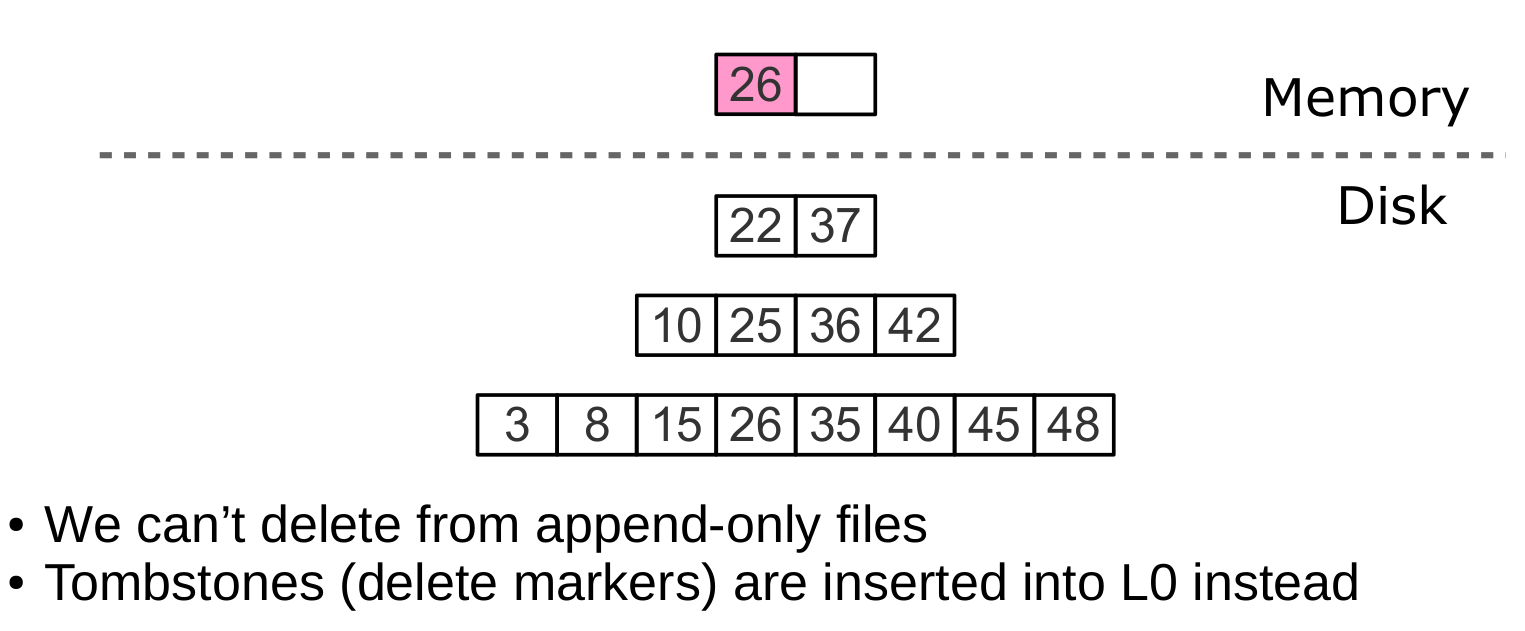
Удаление, шаг 1: вставка в L0
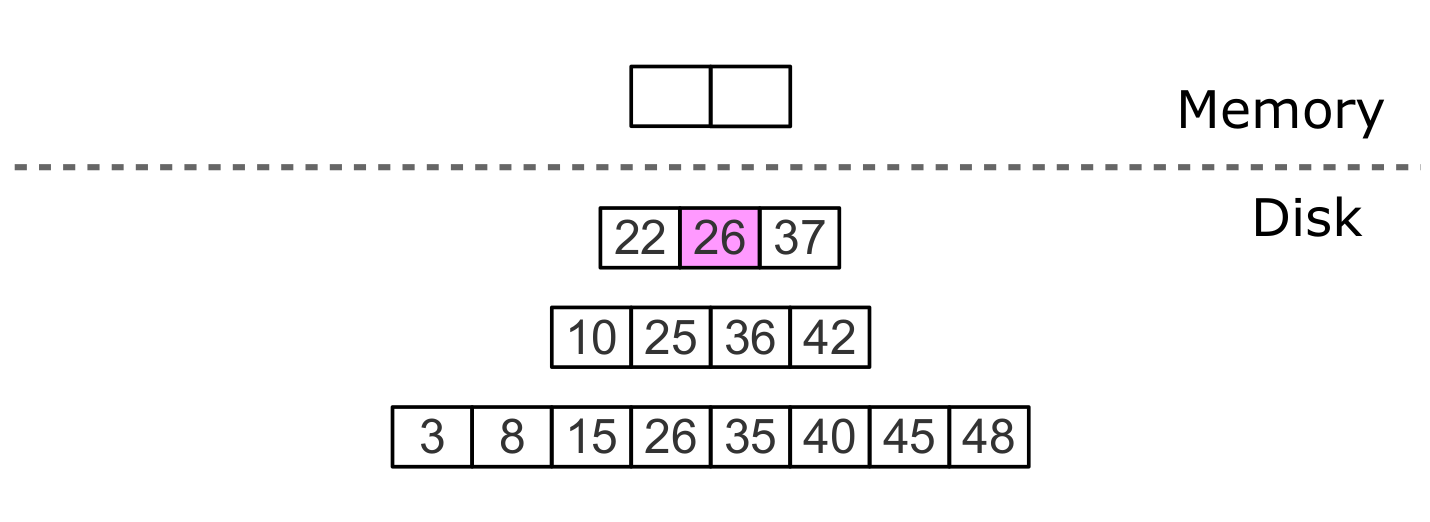
Удаление, шаг 2: tombstone проходит через промежуточные уровни
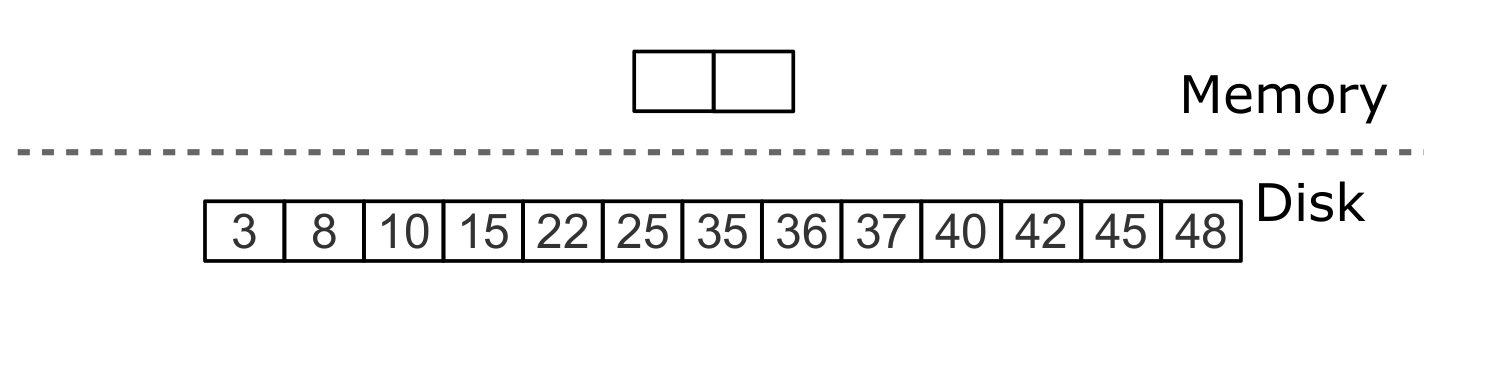
Удаление, шаг 3: при major compaction tombstone удаляется из дерева
Удаления не нужно хранить в L0 (только в памяти). После слияния, затрагивающего последний уровень, удаления можно исключить — отсутствие на нижнем уровне означает отсутствие в дереве.
Оптимизация: если удаление сразу следует за вставкой уникального значения (частый случай при обновлении вторичного индекса), операцию удаления можно фильтровать при слиянии промежуточных уровней.
Преимущества LSM
- Размер файлов: Dump и compaction создают большие файлы (50-100 МБ), что в тысячи раз больше блока B-дерева
- Компрессия: Большой размер позволяет эффективно сжимать данные перед записью
- Фрагментация: Отсутствует, элементы следуют друг за другом без пустот
- Параллелизм: Все операции создают новые файлы, не изменяя старые. Несколько операций могут идти параллельно без конфликтов
- Транзакции: Хранение старых версий позволяет реализовать MVCC (multi-version concurrency control)
Недостатки LSM и их устранение
Непредсказуемая скорость записи
В классическом LSM добавление даже одного элемента может переполнить L0, что приводит к каскадному переполнению уровней и непредсказуемым задержкам.
Решение Tarantool:
Упреждающая запись. Автоматический расчёт необходимого резерва памяти на основе скользящего среднего нагрузки и гистограммы скорости диска.
Пример: L0 = 256 МБ, скорость записи = 10 МБ/с. Для записи требуется 26 секунд. При 10k запросов/сек с элементом 100 байт нужно зарезервировать ~26 МБ. Полезный L0 сокращается до 230 МБ.
Параметры:
- vinyl_timeout = 60 сек (таймаут вставки)
- vinyl_write_threads = 2 (позволяет выполнять dump параллельно с compaction)
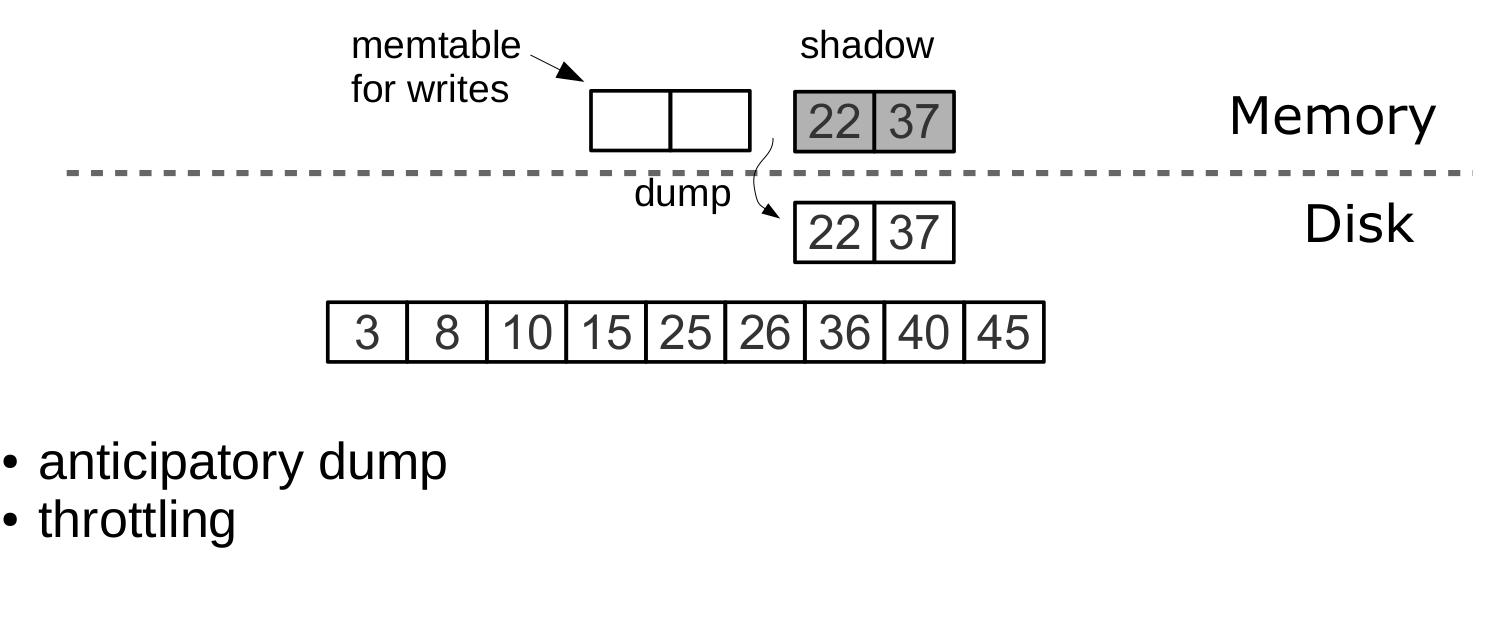
Dump происходит из «shadow» L0, не блокируя новые вставки и чтения
Dump выполняется из “shadow” L0, не блокируя новые вставки и чтения. Освобождение памяти после dump происходит мгновенно благодаря специализированному аллокатору.
Непредсказуемая скорость чтений
Чтение — самая сложная задача в LSM. Главная проблема: большое количество уровней кратно замедляет поиск и требует больше памяти.
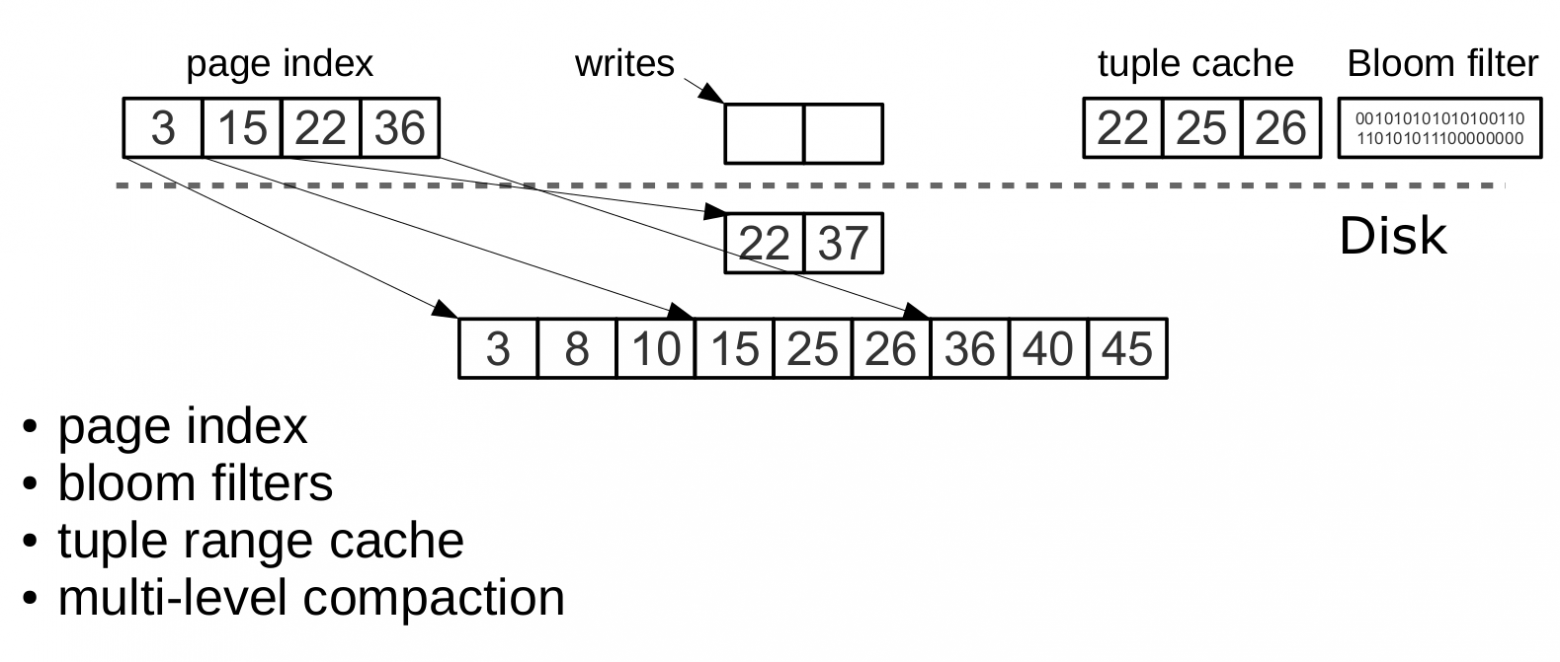
Компрессия и постраничный индекс
При dump или slicing данные разбиваются на страницы. Размер задаётся опцией vinyl_page_size (настраивается для каждого индекса).
Компрессия использует zstd (Facebook). Первый ключ каждой страницы и её смещение в файле добавляются в page index — отдельный файл для быстрого поиска нужной страницы.
Процесс:
- Page index кэшируется в памяти
- Нужная страница найдена за одно чтение из .run-файла
- После чтения и декомпрессии ключ найден бинарным поиском
Чтение и декомпрессия выполняются отдельными потоками (vinyl_read_threads).
Tarantool использует единый формат для всех файлов (.run и .xlog), упрощая backup и восстановление.
Bloom-фильтры
Необходимость проверки отсутствия данных (скрытые чтения) — частая операция:
- Вставка в уникальный индекс требует проверки отсутствия дубликата
- Обновление значения вторичного ключа требует удаления старого значения
Bloom-фильтр — вероятностная структура из нескольких битовых массивов. При записи для каждого ключа вычисляются хэш-функции (обычно 3-5), выставляются биты в массивах. При поиске также вычисляются хэши. Если хоть один бит не установлен, значение в файле отсутствует.
Параметр Tarantool:
- bloom_fpr = 0.05 (5% false positive ratio) по умолчанию
- Автоматически строит оптимальные Bloom-фильтры для полного и частичного ключа
Фильтры хранятся в .index-файле вместе с page index и кэшируются в памяти.
Кэширование
Vinyl использует уникальный для транзакционных систем вид кэша: range tuple cache. Отличие от RocksDB/MySQL:
- Хранит готовые диапазоны значений после чтения и слияния уровней
- Применим как для одиночного ключа, так и для диапазона
- Кэшируются только горячие данные, не страницы
- Память используется оптимально
Размер кэша: vinyl_cache
Управление сборкой мусора
Проблема масштаба:
Дерево из 100 млн записей по 100 байт требует ~10 ГБ на последнем уровне. При слиянии создаётся временный файл такого же размера. Суммарно может потребоваться до 30 ГБ свободного места для 10 ГБ полезных данных.
Проблема распределения:
Если первичный ключ — временной ряд (монотонная последовательность), основные вставки приходятся на правую часть диапазона. Нет смысла переслиивать огромный файл только для добавления нескольких млн записей в хвост.
Если вставки в одну часть диапазона, а чтения из другой, как оптимизировать форму дерева?
Решение: факторизация через ranges
Tarantool создаёт не одно, а множество LSM-деревьев для каждого индекса. Размер каждого поддерева задаётся vinyl_range_size (по умолчанию 1 ГБ). Поддерево называется range.
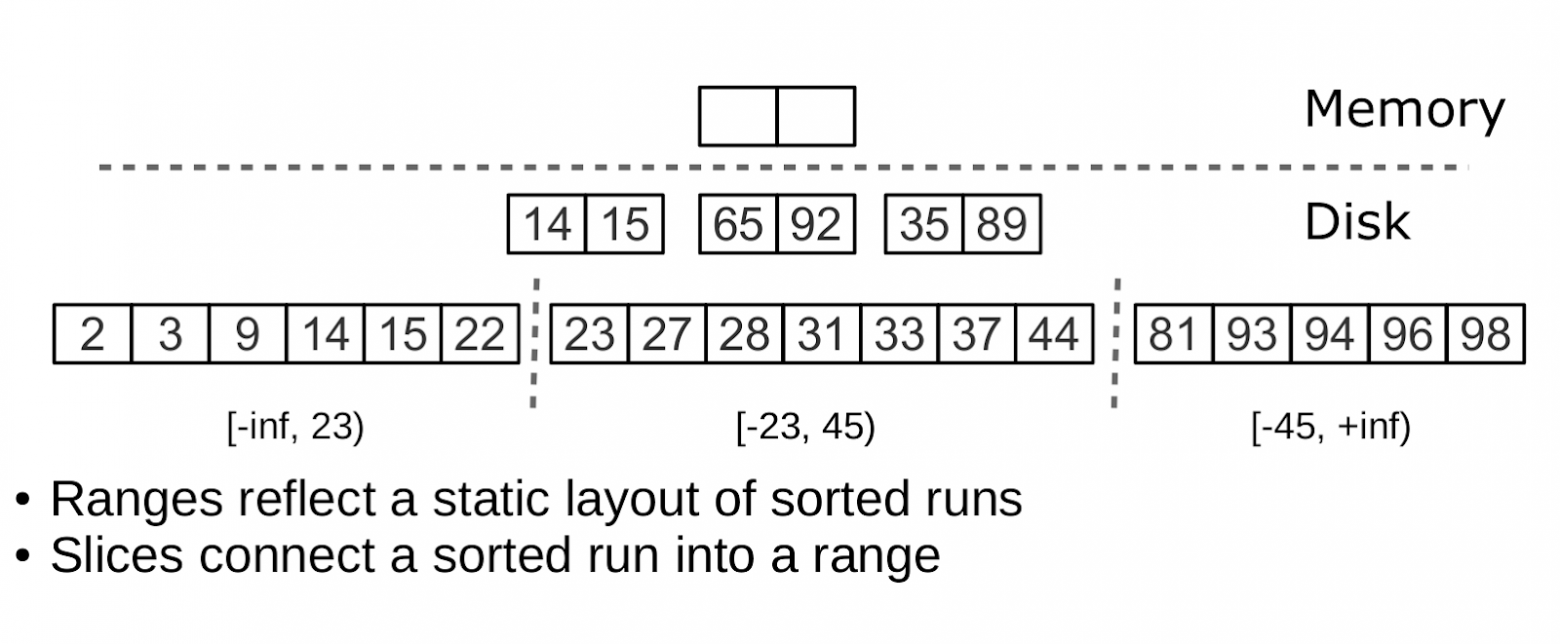
Факторизация больших LSM-деревьев с помощью ранжирования
Процесс:
- Изначально — один range с диапазоном -inf…+inf
- При превышении vinyl_range_size выполняется split по срединному ключу
- Получаются два range: один от -inf до X, другой от X до +inf
- При удалениях и “похудении” выполняется coalesce (объединение соседних деревьев)
Split и coalesce не приводят к слиянию и созданию новых файлов.
Журнал метаданных (.vylog):
- Специальный журнал отслеживает, какой файл принадлежит какому range
- Совместим по формату с .xlog
- Автоматически ротируется при каждом чекпоинте
- Позволяет избежать пересоздания файлов при split/coalesce
Промежуточная сущность — slice:
Ссылка на файл с указанием диапазона значений ключа. Хранится исключительно в журнале метаданных.
- Когда ссылок становится 0 — файл удаляется
- При split/coalesce создаются новые slice, старые удаляются
Журнал хранит записи: <id дерева, id слайса> или <id слайса, id файла, min, max>.
Тяжёлая работа разбиения откладывается до compaction и выполняется автоматически.
Преимущества:
- Независимое управление L0, dump и compaction для каждого range
- Процессы управляемые и предсказуемые
- Мгновенные операции truncate и drop (работают только с журналом метаданных)
- Фоновое удаление мусора выполняется независимо
Расширенные возможности Vinyl
Upsert
Операция, объединяющая insert и update без скрытых чтений. Содержит:
- Значение по умолчанию (если данных нет)
- Список операций обновления (если значение существует)
На этапе выполнения транзакции Tarantool сохраняет всю операцию в LSM. “Выполняется” она только при слиянии.

Проблема валидации: Некоторые проверки требуют старых данных (например, прибавление числа к строке).
Ограничения: Не применима при наличии вторичных ключей или триггеров (неизбежны скрытые чтения).
Реальный случай:
В production: огромный набор ключей, текущее время как значение. Вставки либо вставляли ключ, либо обновляли время. Чтения редкие.
После пары дней: процесс потреблял 100% CPU, производительность упала до нуля.
Причина: распределение запросов существенно отличалось. Большая часть ключей обновлялась 1-2 раза в сутки, но были горячие ключи с десятками тысяч обновлений. При чтении по такому ключу требовалось прочитать и проиграть историю из десятков тысяч upsert’ов.
L0 не выталкивалась на диск (памяти было достаточно), поэтому до слияния не доходило.
Решение: Фоновый процесс “упреждающих” чтений для ключей с накоплением >10 upsert’ов. Замена стэка на прочитанное значение.
Вторичные ключи
Даже replace при вторичных ключах требует чтения старого значения: его нужно независимо удалить из вторичных индексов.
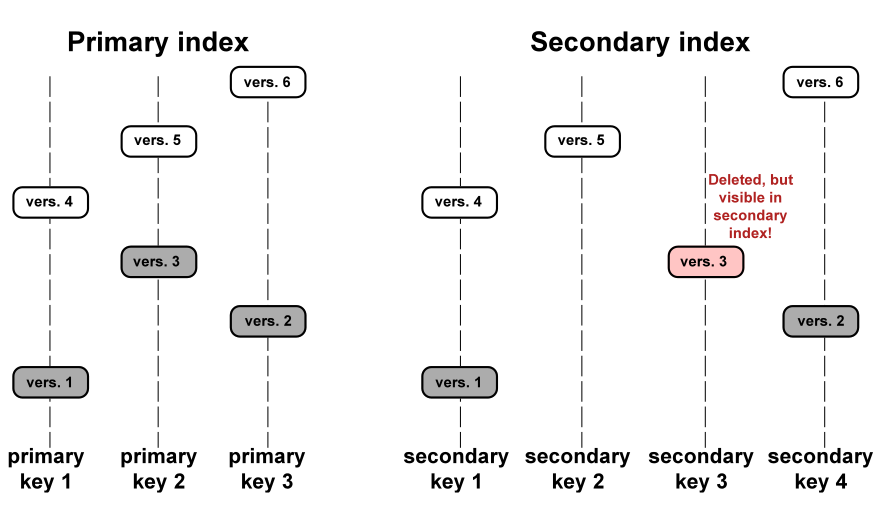
Оптимизация: если вторичные индексы не уникальны, удаление “мусора” можно перенести в фазу слияния (реализовано в Vinyl).
Транзакции
Append-only природа LSM позволила реализовать полноценные сериализуемые транзакции.
- Read-only запросы используют старые версии данных, не блокируя запись
- Менеджер реализует класс MVTO: при конфликте побеждает первая завершённая
- Блокировок и дедлоков нет
- Поддержка gap locks (редко встречается в NoSQL)
Развитие менеджера — в ближайших планах.
Заключение
Tarantool с Vinyl прошёл испытание боем в Mail.Ru Group и вне её. Используется в интернет-компаниях, банках, телекоммуникационных компаниях, промышленном секторе. Доступна для скачивания на сайте проекта.
Проект активно растёт и ищет единомышленников для создания СУБД мирового уровня.