How Tarantool works with memory
This is the third part of a four-part transcript of my talk at Highload conference 2015. For the previous part, see this post.
This part of the talk is about memory. After all, Tarantool is primarily an in-memory DBMS, so we pay a lot of attention to memory-related issues.

While memory management is perhaps the central problem for an in-memory database, I was only able to approach it after having moved the general issues of Part 1 and Part 2 out of the way. So, in this part, I will try to demonstrate how smart solutions of seemingly unrelated problems provided us with opportunities and expanded our space of choices when dealing with this central problem. By encapsulating all inter-thread communication into message exchange, for most of the memory we use within Tarantool we don’t need to provide concurrent access from multiple threads. And ensuring that a single-threaded memory manager is as efficient as possible is a much easier task to do!
Before explaining Tarantool memory hierarchy, let me formalize the requirements for it. On the introductory slide for this part, I listed the requirements it doesn’t have: the ones for a classical memory manager. Now let me list the database-specific demands for a memory manager.

First of all, our unique requirement is support for quotas. We never exceed the memory limit set by the user. A very frequent question from our community is, “Does your system crash if it runs out of memory?”. It might, if there’s a bug in the source code. But normally, if there is no free memory, the system just stops writing data but goes on processing read requests. That’s one of the tasks fulfilled by our memory manager.
Task number two is log compaction. To speed up the recovery process, we need to periodically save a snapshot of our entire memory to disk, that is we need consistent memory snapshots. Moreover, we need these snapshots to support the so-called interactive transactions, the ones started on the client side. We also need the snapshots to implement classical multiversion concurrency control.

The main design principle of Tarantool memory manager is that there is no all-purpose manager at all. We realize that memory management is a difficult problem, where many special cases have very efficient solutions, while a generic memory manager is extremely difficult to create. So, instead of having a single all-purpose manager, we built a family of managers that work well together. Internally, we are now able to address every difficult problem with a purposefully designed solution.
Here’s how this family is organized. All allocators are hierarchically arranged in such a way that higher-level nodes serve as memory providers for lower-level ones. At the top of the hierarchy, we have a global object called memory quota. In theory, there can be many objects of this kind, but currently we use only one, or, at a pinch, two: a memory quota to actually store data and a quota for runtime needs, such as Lua programs and client connections. Since runtime normally does not consume much memory, this second quota is reserved for future use: it is unlimited.
A quota object stores two values: allocatable memory size (that is the maximum size that users can allocate) and allocated memory size (that is how much memory is actually allocated). Quota is concurrent and can be shared by all our threads.
Quota consumers are so-called arenas. Here’s what an arena is:

It’s a memory manager that can allocate and free only huge 4 MB memory chunks. The chunks could be either process-private or shared between many processes. Arena’s task is to take the memory from the operating system, account memory usage in the quota and provide it to lower levels in the hierarchy. It also guarantees the aligned address space of the allocated blocks, which is useful when performing pointer arithmetic in a lower-level allocator. A perfect program address space has low fragmentation. For this purpose, an arena pre-allocates a large part - for example, tens of gigabytes - of the address space at startup, but can allocate more if the quota is increased after the startup.
An arena can be used from multiple threads; in other words, one arena can be a memory source for many threads.
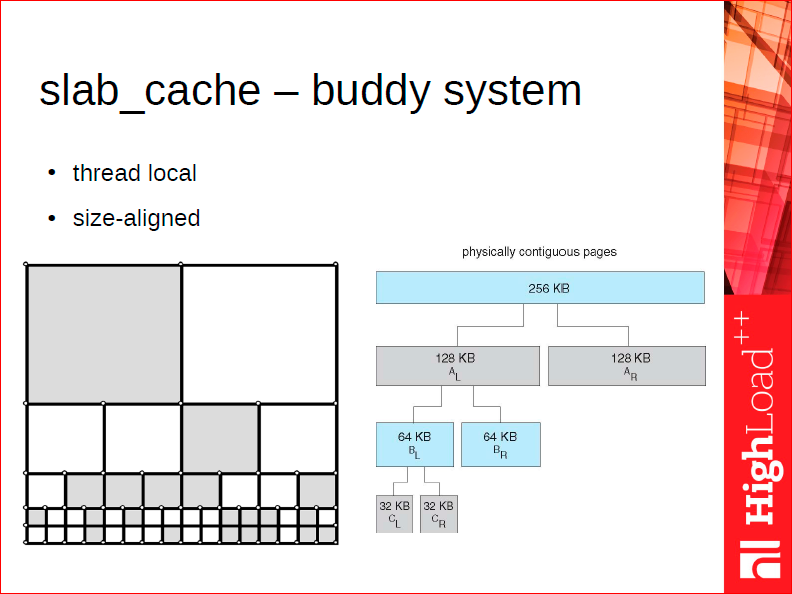
The next object down in the hierarchy is the slab cache, which is the first thread-local allocator and it implements a buddy system. An arena provides only large memory chunks of the same size, while a slab cache knows how to slice a large chunk taken from the arena into smaller pieces, and distribute these pieces as independent allocations.
A buddy allocator works as follows. One very serious issue with memory allocation is fragmentation: we allocate memory in a lot of chunks, then free some of them - as a result, we have a number of non-contiguous unallocated regions. Now, suppose we took a large 4 MB chunk of memory from slab_arena. A buddy allocator can only return chunks of the size that is a power of two, from 2 KB to 4 MB (the largest size). Its main job, after you free a chunk, is to find this chunk’s neighbor, or buddy. If the buddy is also unallocated, it gets merged with the freed chunk, which is a cheap way of defragmenting memory after it’s deallocated. To sum up, your memory remains defragmented for a long time since the allocator knows how to efficiently keep it that way.
Besides implementing a buddy system for chunk management, a slab cache, as follows from its name, is also a cache: it keeps a thread-local cache of recently freed chunks, so requesting a chunk from it normally does not involve usage of concurrent data structures. It also preserves memory address alignment for the chunks it returns. That is, if you take a 2 KB chunk from it, you can be sure the address is 2 KB aligned - a handy property if you want to put a common header in the beginning of the chunk.
Slab arena’s chunk size sets a cap on the slab cache’s chunk size, which in turn sets a cap on the largest tuple a Tarantool allocator can provide. This is unfortunate, and in a future release we’ll learn how to split large tuples into multiple smaller chunks, so that Tarantool can store tuples of any size.

Next level down is a classical pool allocator - object pool - which uses a slab cache as its source of memory. It takes aligned chunks (of, say, 2 KB or 4 KB) from the slab cache and uses these chunks to allocate smaller objects. It stores its local state in the beginning of the chunk, but otherwise doesn’t incur any memory overhead at all. It has a limitation, too: it can’t allocate objects of different sizes.
Suppose we have an object - a connection, a fiber or a user - that is quite hot, that is it’s frequently allocated and deallocated, sometimes hundreds of thousands of times per second. We want the allocation of suchlike objects to be as cheap as stack-based allocation - that’s where dedicated object pools come into play. However, such pools alone are sometimes not enough, because we simply can’t know the object size beforehand.
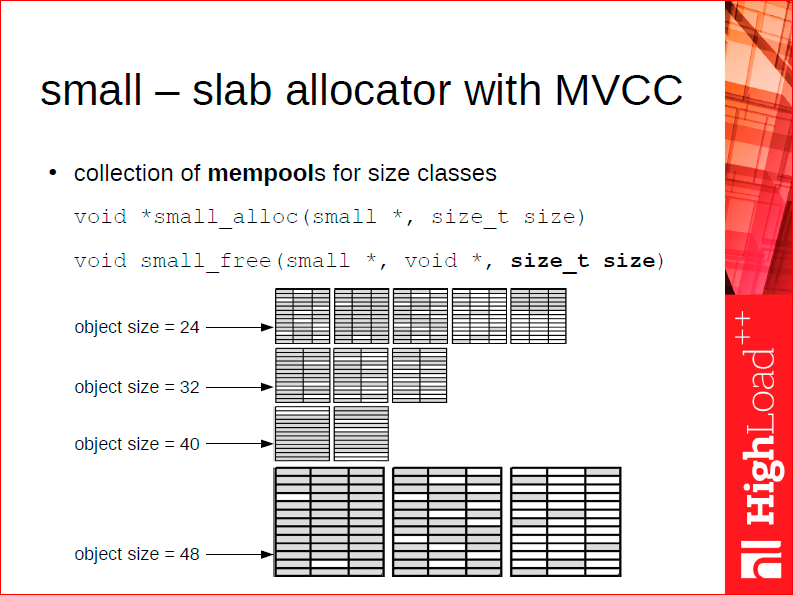
So for tuple data, we use a smartly tweaked classical slab allocator, based on an array of object pools. Normally, a slab allocator doesn’t know the size of the object being deallocated, whereas we have no such limitation - we have to store the size inside the object for different purposes anyway. Given that, we can use slabs of different sizes for different object size classes, and determine the slab size and location of the header from the object size. On the slide above, you can see 24-, 32- and 40-byte objects - we use slabs of, say, 4 KB for all of them; for 48-byte objects, however, the slab size is already 8 KB. This way, we can have a lot of object pools for different tuple sizes - thankfully, each pool does not waste memory, even if it’s nearly empty.
Let me elaborate on that. A typical problem of a regular slab allocator is that it has to create at least one slab for each size class. If you have a system with 200 size classes and a 4 MB slab size for every class, once you allocate only one object per size class - lo and behold - you end up with 800 MB of memory taken from the operating system, with only a few kilobytes of it actually used. That’s why using a regular slab allocator, such as jemalloc, is all about a tradeoff between internal and external fragmentation, that is how many or how few size classes to have. In case of Tarantool, we can afford to have a slab class per each 8 bytes of tuple size, which means internal fragmentation is nearly non-existent.
To further reduce memory fragmentation, similarly to a classical slab allocator, our own allocator prefers addresses in a lower part of the address space for each new allocation. If your system has worked for a long time, then freed some memory and after that allocated some more memory, we try to move the tuple data to the bottom of the address space and return chunks at the top of the address space, which have no tuples at all, back to the slab cache.

Finally, let me mention a few specialized allocators useful for special cases.
We have a wonderful allocator that can’t free memory. Allocate and forget - pretty cool, huh? In fact, you can only free all the allocated memory at once. This is a region allocator, which works similarly to an object stack. GCC has lots of similar allocators in different systems, many of them open-source. One important difference of the Tarantool system is that its allocators are arranged hierarchically, that is our region allocator is also using the slab cache as a provider of larger memory chunks.
For the Vinyl storage engine, we use a log-structured allocator, similar to a region allocator with a twist. You can’t free an individual object, but you can free all objects allocated before a certain point in time. This strategy works well with log-structured merge trees, in which you eventually dump all allocated objects to non-volatile storage and free them. By using the log-structured allocator, we avoid the long process of deleting the dumped objects one by one.
We went on to make the library available on GitHub independently from Tarantool at github.com/tarantool/small. You can take a look at its source code - it’s relatively lightweight, which I consider an advantage. Whatever details I’ve omitted in my talk can be read in the repository.
So, that’s the foundation on which we’ll be building our structures for data storage. Part 4, which is more technically advanced than the rest of my talk, will be about just that.